Metasrv
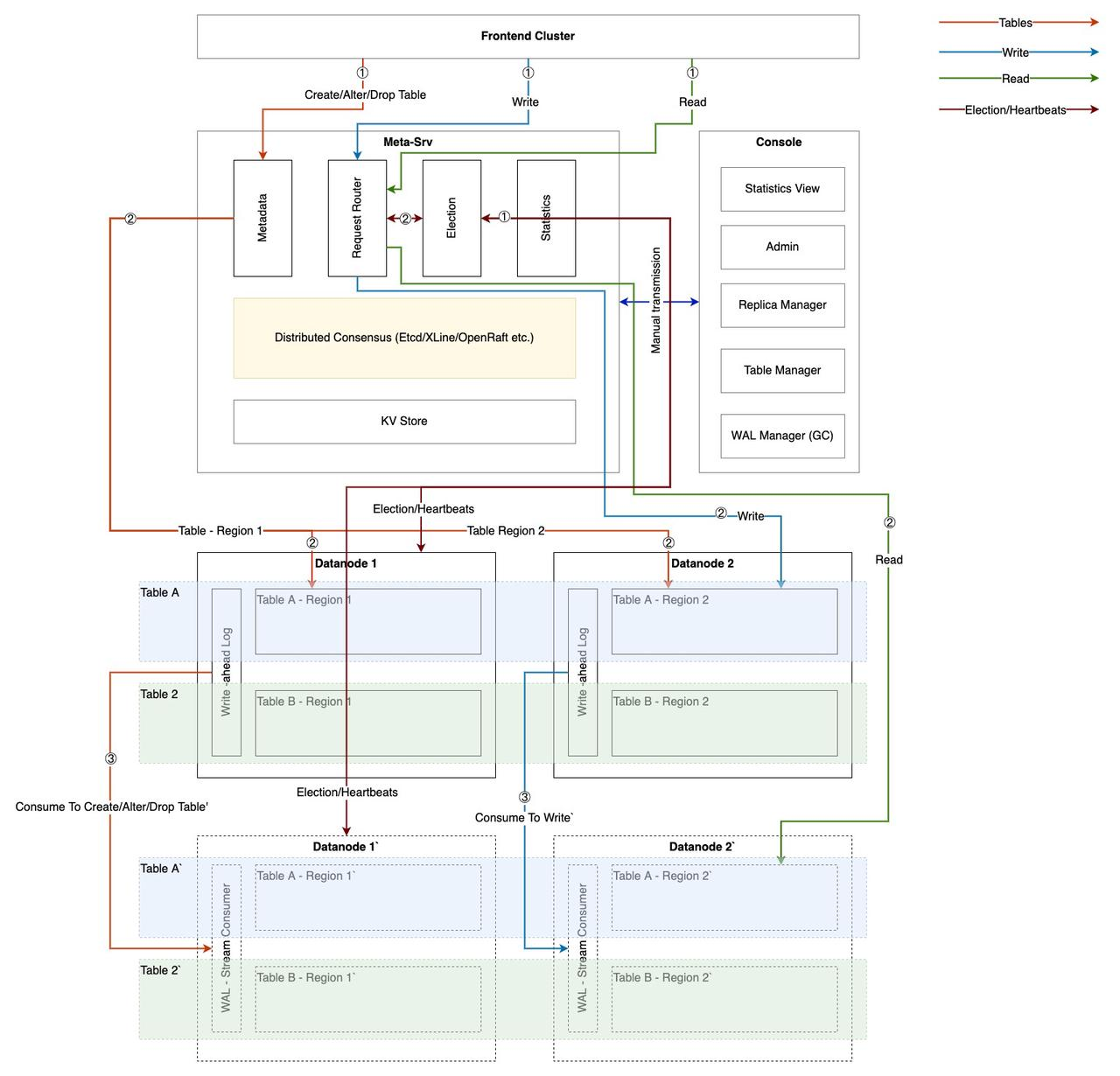
Metasrv 包含什么
- 存储元数据(Catalog, Schema, Table, Region 等)
- 请求路由器。它告诉前端在哪里写入和读取数据。
- 数据节点的负载均衡,决定谁应该处理新的表创建请求,更准确地说,它做出资源分配决策。
- 选举与高可用性,GreptimeDB 设计为 Leader-Follower 架构,只有 leader 节点可以写入,而 follower 节点可以读取,follower 节点的数量通常 >= 1,当 leader 不可用时,follower 节点需要能够快速切换为 leader。
- 统计数据收集(通过每个节点上的心跳报告),如 CPU、负载、节点上的表数量、平均/峰值数据读写大小等,可用作分布式调度的基础。
前端如何与 Metasrv 交互
首先,请求路由器中的路由表结构如下(注意这只是逻辑结构,实际存储结构可能不同,例如端点可能有字典压缩)。
table_A
table_name
table_schema // 用于物理计划
regions
region_1
mutate_endpoint
select_endpoint_1, select_endpoint_2
region_2
mutate_endpoint
select_endpoint_1, select_endpoint_2, select_endpoint_3
region_xxx
table_B
...
创建表
- 前端发送
CREATE TABLE请求到 Metasrv。 - 根据请求中包含的分区规则规划 Region 数量。
- 检查数据节点可用资源的全局视图(通过心跳收集)并为每个 Region 分配一个节点。
- 前端创建表并在成功创建后将
Schema存储到 Metasrv。
Insert
- 前端从 Metasrv 获取指定表的路由。注意,最小的路由单元是表的路由(多个 Region),即包含该表所有 Region 的地址。
- 最佳实践是前端首先从本地缓存中获取路由并将请求转发到数据节点。如果路由不再有效,则数据节点有义务返回
Invalid Route错误,前端重新从 Metasrv 获取最新数据并更新其缓存。路由信息不经常变化,因此,前端使用惰性策略维护缓存是足够的。 - 前端处理可能包含多个表和多个 Region 的一批写入,因此前端需要根据“路由表”拆分用户请求。
Select
- 与
Insert类似,前端首先从本地缓存中获取路由表。 - 与
Insert不同,对于Select,前端需要从路由表中提取只读节点(follower),然后根据优先级将请求分发到 leader 或 follower 节点。 - 前端的分布式查询引擎根据路由信息分发多个子查询任务并聚合查询结果。
Metasrv 架构
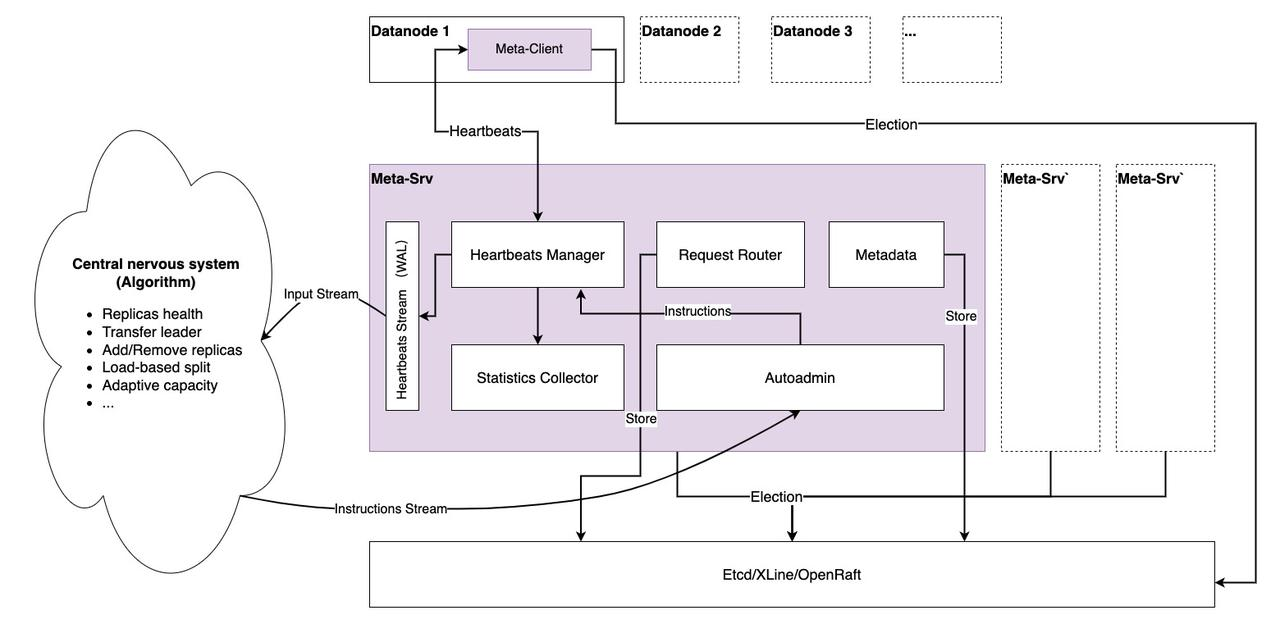
分布式共识
如你所见,Metasrv 依赖于分布式共识,因为:
- 首先,Metasrv 必须选举一个 leader,数据节点只向 leader 发送心跳,我们只使用单个 Metasrv 节点接收心跳,这使得基于全局信息进行一些计算或调度变得容易且快速。至于数据节点如何连接到 leader,这由 MetaClient 决定(使用重定向,心跳请求变为 gRPC 流,使用重定向比转发更不容易出错),这对数据节点是透明的。
- 其次,Metasrv 必须为数据节点提供选举 API,以选举“写入”和“只读”节点,并帮助数据节点实现高可用性。
- 最后,
Metadata、Schema和其他数据必须在 Metasrv 上可靠且一致地存储。因此,基于共识的算法是存储它们的理想方法。
对于 Metasrv 的第一个版本,我们选择 Etcd 作为共识算法组件(Metasrv 设计时考虑适应不同的实现,甚至创建一个新的轮子),原因如下:
- Etcd 提供了我们需要的 API,例如
Watch、Election、KV等。 - 我们只执行两个分布式共识任务:选举(使用
Watch机制)和存储(少量元数据),这两者都不需要我们定制自己的状态机,也不需要基于 raft 定制自己的状态机;少量数据也不需要多 raft 组支持。 - Metasrv 的初始版本使用 Etcd,使我们能够专注于 Metasrv 的功能,而不需要在分布式共识算法上花费太多精力,这提高了系统设计(避免与共识算法耦合)并有助于初期的快速开发,同时通过良好的架构设计,未来可以轻松接入优秀的共识算法实现。
心跳管理
数据节点与 Metasrv 之间的主要通信方式是心跳请求/响应流,我们希望这是唯一的通信方式。这个想法受到 TiKV PD 设计的启发,我们在 RheaKV 中有实际经验。请求发送其状态,而 Metasrv 通过心跳响应发送不同的调度指令。
心跳可能携带以下数据,但这不是最终设计,我们仍在讨论和探索究竟应该收集哪些数据。
service Heartbeat {
// 心跳,心跳可能有很多内容,例如:
// 1. 要注册到 Metasrv 并可被其他节点发现的元数据。
// 2. 一些性能指标,例如负载、CPU 使用率等。
// 3. 正在执行的计算任务数量。
rpc Heartbeat(stream HeartbeatRequest) returns (stream HeartbeatResponse) {}
}
message HeartbeatRequest {
RequestHeader header = 1;
// 自身节点
Peer peer = 2;
// leader 节点
bool is_leader = 3;
// 实际报告时间间隔
TimeInterval report_interval = 4;
// 节点状态
NodeStat node_stat = 5;
// 此节点中的 Region 状态
repeated RegionStat region_stats = 6;
// follower 节点和状态,在 follower 节点上为空
repeated ReplicaStat replica_stats = 7;
}
message NodeStat {
// 此期间的读取容量单位
uint64 rcus = 1;
// 此期间的写入容量单位
uint64 wcus = 2;
// 此节点中的表数量
uint64 table_num = 3;
// 此节点中的 Region 数量
uint64 region_num = 4;
double cpu_usage = 5;
double load = 6;
// 节点中的读取磁盘 I/O
double read_io_rate = 7;
// 节点中的写入磁盘 I/O
double write_io_rate = 8;
// 其他
map<string, string> attrs = 100;
}
message RegionStat {
uint64 region_id = 1;
TableName table_name = 2;
// 此期间的读取容量单位
uint64 rcus = 3;
// 此期间的写入容量单位
uint64 wcus = 4;
// 近似 Region 大小
uint64 approximate_size = 5;
// 近似行数
uint64 approximate_rows = 6;
// 其他
map<string, string> attrs = 100;
}
message ReplicaStat {
Peer peer = 1;
bool in_sync = 2;
bool is_learner = 3;
}
Central Nervous System (CNS)
我们要构建一个算法系统,该系统依赖于每个节点的实时和历史心跳数据,应该做出一些更智能的调度决策并将其发送到 Metasrv 的 Autoadmin 单元,该单元分发调度决策,由数据节点本身或更可能由 PaaS 平台执行。
工作负载抽象
工作负载抽象的级别决定了 Metasrv 生成的调度策略(如资源分配)的效率和质量。
DynamoDB 定义了 RCUs 和 WCUs(读取容量单位/写入容量单位),解释说 RCU 是一个 4KB 数据的读取请求,WCU 是一个 1KB 数据的写入请求。当使用 RCU 和 WCU 描述工作负载时,更容易实现性能可测量性并获得更有信息量的资源预分配,因为我们可以将不同的硬件能力抽象为 RCU 和 WCU 的组合。
然而,GreptimeDB 面临比 DynamoDB 更复杂的情况,特别是 RCU 不适合描述需要大量计算的 GreptimeDB 读取工作负载。我们正在努力解决这个问题。