分布式查询
我们知道在 GreptimeDB 中数据是如何分布的(参见“表分片”),那么如何查询呢?在 GreptimeDB 中,分布式查询非常简单。简单来说,我们只需将查询拆分为子查询,每个子查询负责查询表数据的一个部分,然后将所有结果合并为最终结果。这是一种典型的“拆分 - 合并”方法。具体来说,让我们从查询到达 frontend 开始。
当查询到达 frontend 时,它首先被解析为 SQL 抽象语法树(AST)。我们遍历 AST,并从中生成逻辑计划。顾名思义,逻辑计划只是如何“逻辑地”执行查询的“提示”,它不能被直接运行,因此我们进一步从中生成可执行的物理计划。物理计划是一种类似树形的数据结构,每个节点实际上表示查询的执行方法。一旦我们从上到下运行物理计划树,结果数据将从叶子到根流动,被合并或计算。最终,我们在根节点的输出处得到了查询的结果。
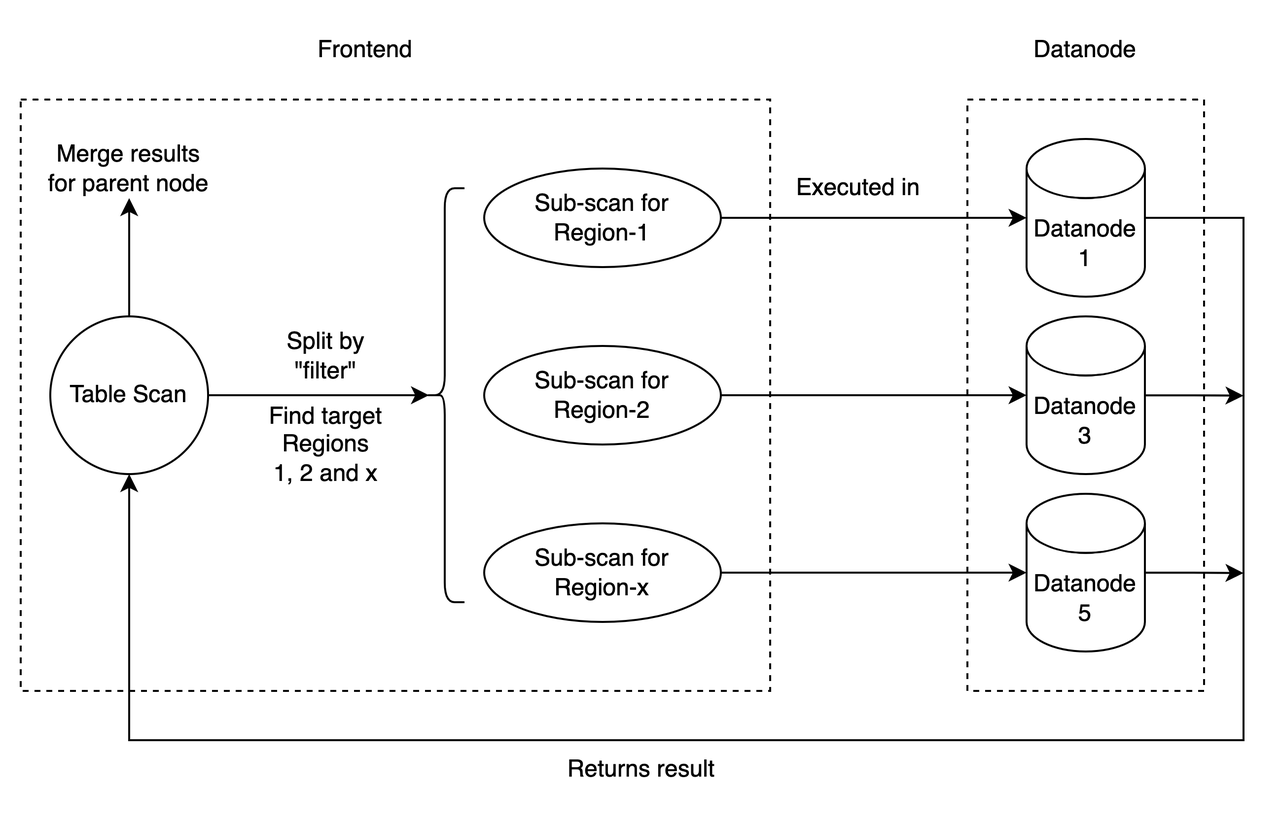
到目前为止,这只是一个典型的“volcano”查询执行模型,你可以在几乎每个 SQL 数据库中看到这种模型。那么“分布式”是在哪里发生的呢?这全部发生在一个名为“TableScan”的物理计划节点中。TableScan 是物理计划树中的一个叶子节点,它负责扫描表的数据(就像它的名称所暗示的)。当 frontend 即将扫描表时,它首先需要根据每个 region 的数据范围将表扫描拆分为较小的扫描。
表的所有 region 都有它们存储数据的范围。以下表为例:
CREATE TABLE my_table (
a INT,
others STRING,
)
PARTITION ON COLUMNS (a) (
n < 10,
n >= 10 AND n < 20,
n >= 20
)
my_table 表创建时被设定了 3 个分区。在 GreptimeDB 的当前实现中,将为该表创建 3 个 region(分区与 region 的比例为 1:1)。这 3 个区域将分别包含以下范围:"[-∞, 10)", "[10, 20)" 和 "[20, +∞)"。例如,如果提供了值 "42",我们将搜索这些范围,并找到包含该值的相应的 region(在此示例中为第 3 个 region)。
对于查询,我们使用“过滤器”来查找 region。 "过滤器"是 "WHERE" 子句中的条件。例如,查询 SELECT * FROM my_table WHERE a < 10 AND b > 10,其“过滤器”为“a < 10 AND b > 10”。然后我们检查这些范围,找出包含满足过滤器条件的值的所有 region。
如果某个查询没有任何过滤器,则将其视为全表扫描。
找到所需的区域后,我们只需在其中组装子扫描。通过这种方式,我们将查询拆分为子查询,每个子查询都获取表数据的一部分。子查询在 datanode 中执行,并在 frontend 中等待完成。它们的结果将合并为表扫描请求的最终返回。
下面这张图片总结了分布式查询执行的过程: