概述
作为分布式数据库,GreptimeDB 提供了不同的灾难恢复(DR)解决方案。
本文档包括以下内容:
- DR 中的基本概念
- GreptimeDB 中备份与恢复(BR)的部署架构。
- GreptimeDB 的 DR 解决方案。
- DR 解决方案的比较。
基本概念
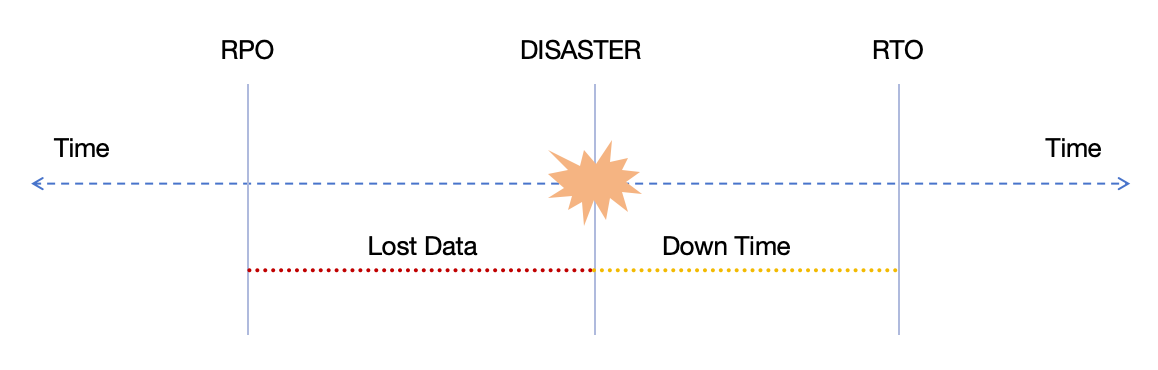
- 恢复时间目标(RTO):指灾难发生后业务流程可以停止的最长时间,而不会对业务产生负面影响。
- 恢复点目标(RPO):指自上一个数据恢复点以来可接受的最大时间量,决定了上一个恢复点和服务中断之间可接受的数据丢失量。
下图说明了这两个概念:
- 预写式日志(WAL):持久记录每个数据修改,以确保数据的完整性和一致性。
GreptimeDB 存储引擎是一个典型的 LSM 树:
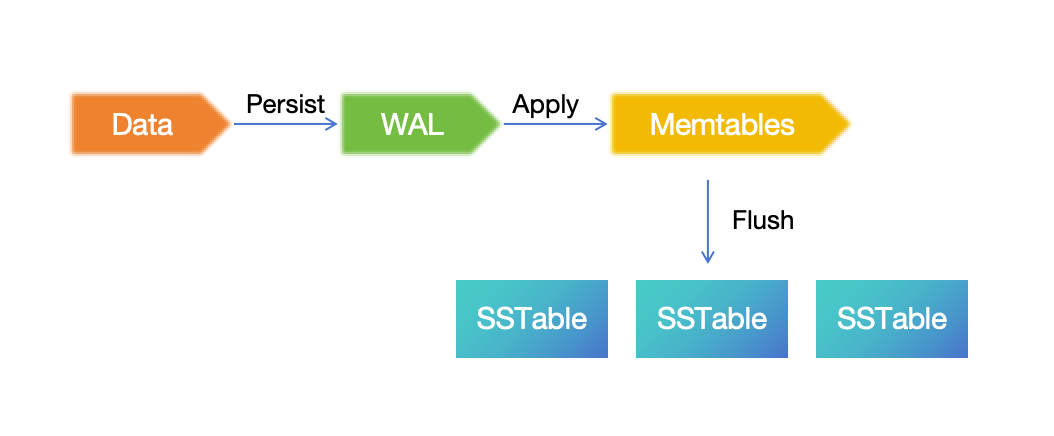
写入的数据首先持久化到 WAL,然后应用到内存中的 Memtable。 在特定条件下(例如超过内存阈值时), Memtable 将被刷新并持久化为 SSTable。 因此,WAL 和 SSTable 的备份恢复是 GreptimeDB 灾难恢复的关键。
- Region:表的连续段,也可以被视为某些关系数据库中的分区。请阅读表分片以获取更多详细信息。
组件架构
GreptimeDB
在深入了解具体的解决方案之前,让我们从灾难恢复的角度看一下 GreptimeDB 组件的架构:
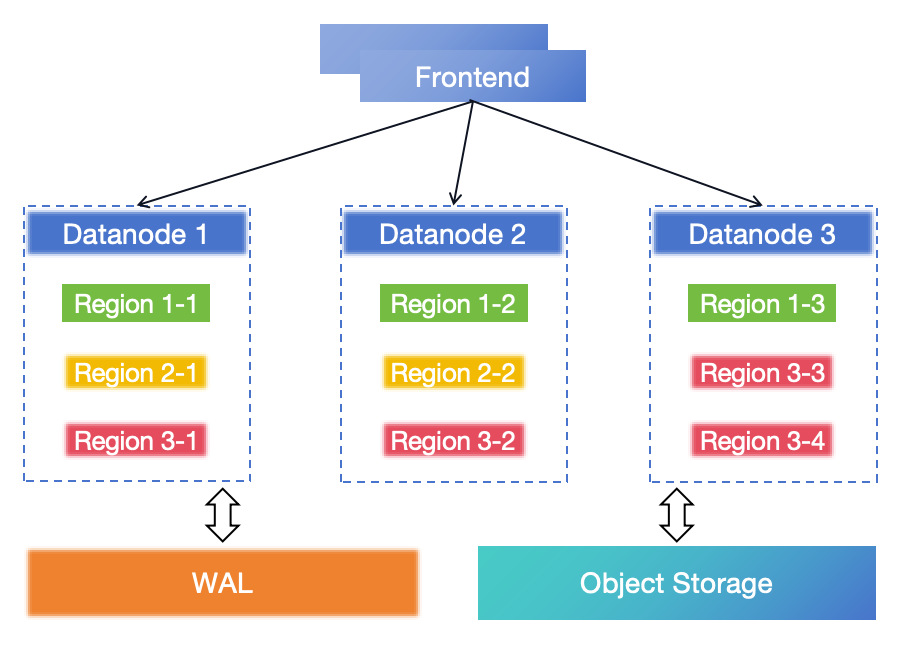
GreptimeDB 基于存储计算分离的云原生架构设计:
- Frontend:数据插入和查询的服务层,将请求转发到 Datanode 并处理和合并 Datanode 的响应。
- Datanode:GreptimeDB 的存储层,是一个 LSM 存储引擎。Region 是在 Datanode 中存储和调度数据的基本单元。Region 是一个表分区,是一组数据行的集合。Region 中的数据保存在对象存储中(例如 AWS S3)。未刷新的 Memtable 数据被写入 WAL,并可以在灾难发生时恢复。
- WAL:持久化内存中未刷新的 Memtable 数据。当 Memtable 被刷新到 SSTable 文件时,WAL 将被截断。它可以是基于本地磁盘的(本地 WAL)或基于 Kafka 集群的(远程 WAL)。
- 对象存储:持久化 SSTable 数据和索引。
GreptimeDB 将数据存储在对象存储(如 AWS S3)或兼容的服务中,这些服务在年度范围内提供了 99.999999999% 的持久性和 99.99% 的可用性。像 S3 这样的服务提供了单区域或跨区域的复制,天然具备灾难恢复能力。
同时,WAL 组件是可插拔的,例如使用 Kafka 作为 WAL 服务以提供成熟的灾难恢复解决方案。
备份与恢复
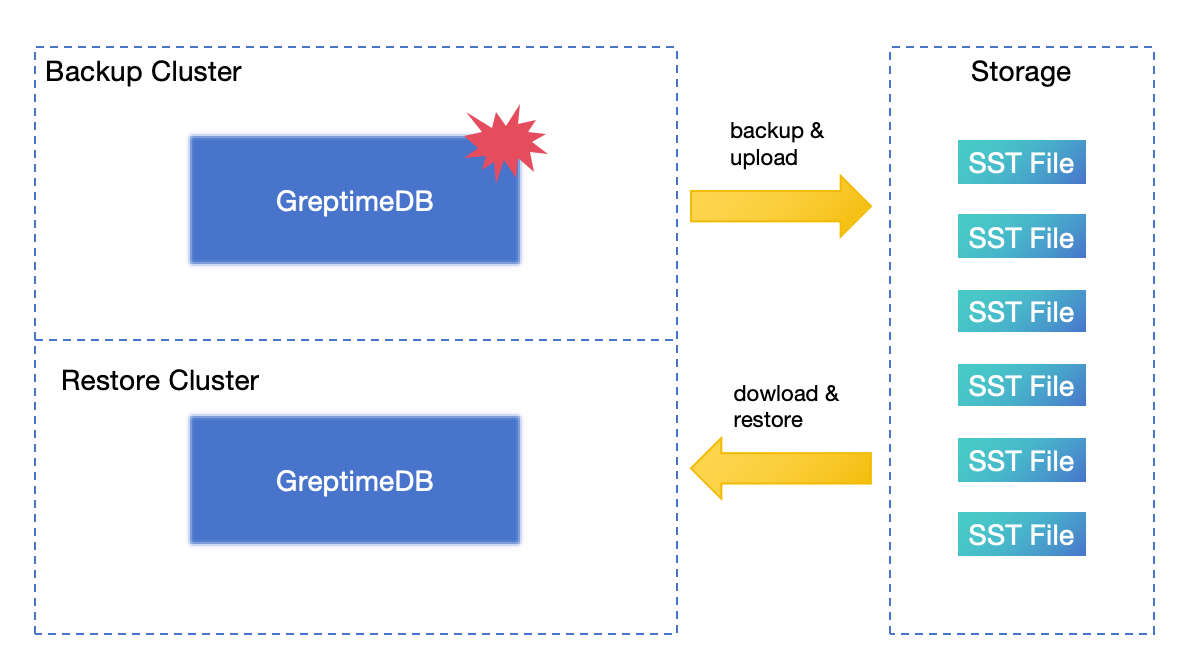
备份与恢复(BR)工具可以在特定时间对数据库或表进行完整快照备份,并支持增量备份。 当集群遇到灾难时,你可以使用备份数据恢复集群。 一般来说,BR 是灾难恢复的最后手段。
解决方案介绍
GreptimeDB Standalone 的 DR 方案
如果 GreptimeDB Standalone 在本地磁盘上运行 WAL 和数据,那么:
- RPO:取决于备份频率。
- RTO:在 Standalone 没有意义,主要取决于要恢复的数据大小、故障响应时间和操作基础设施。
选择将 GreptimeDB Standalone 部署到具有备份和恢复解决方案的 IaaS 平台中是一个很好的开始,例如亚马逊 EC2(结合 EBS 卷)提供了全面的备份和恢复解决方案。
但是如果使用远程 WAL 和对象存储运行 Standalone,有一个更好的 DR 解决方案:
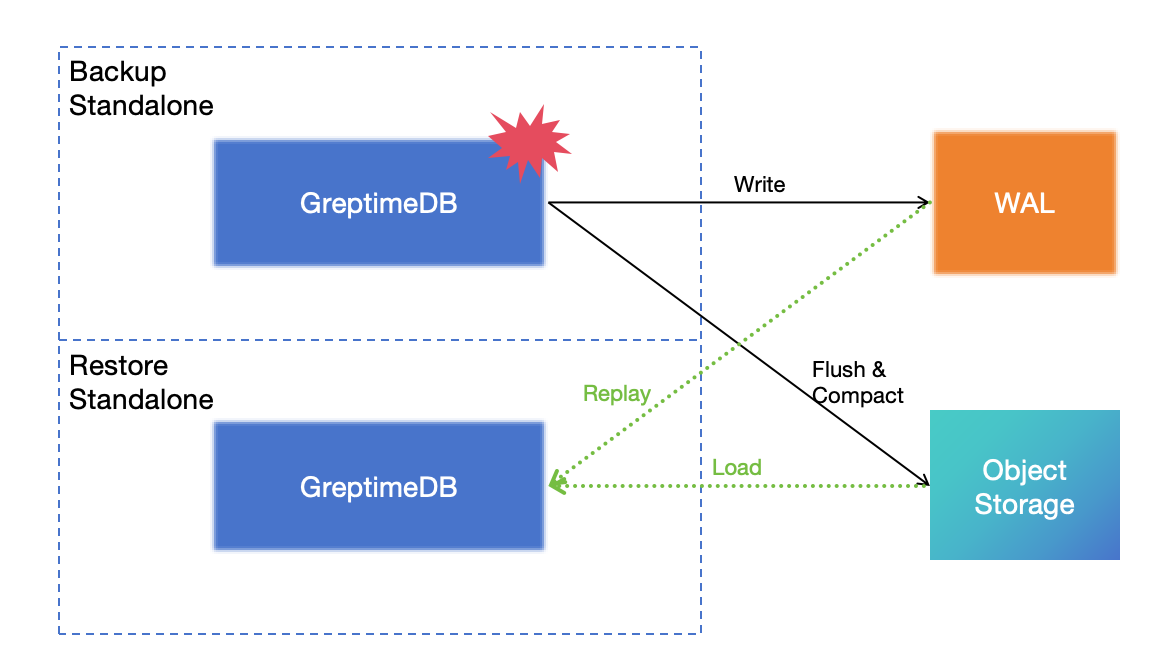
将 WAL 写入 Kafka 集群,并将数据存储在对象存储中,因此数据库本身是无状态的。 在影响独立数据库的灾难事件发生时,你可以使用远程 WAL 和对象存储来恢复它。 此方案能实现 RPO=0 和分钟级 RTO。
有关此解决方案的更多信息,请参阅独立模式的 DR 解决方案。
基于双活互备的 DR 解决方案
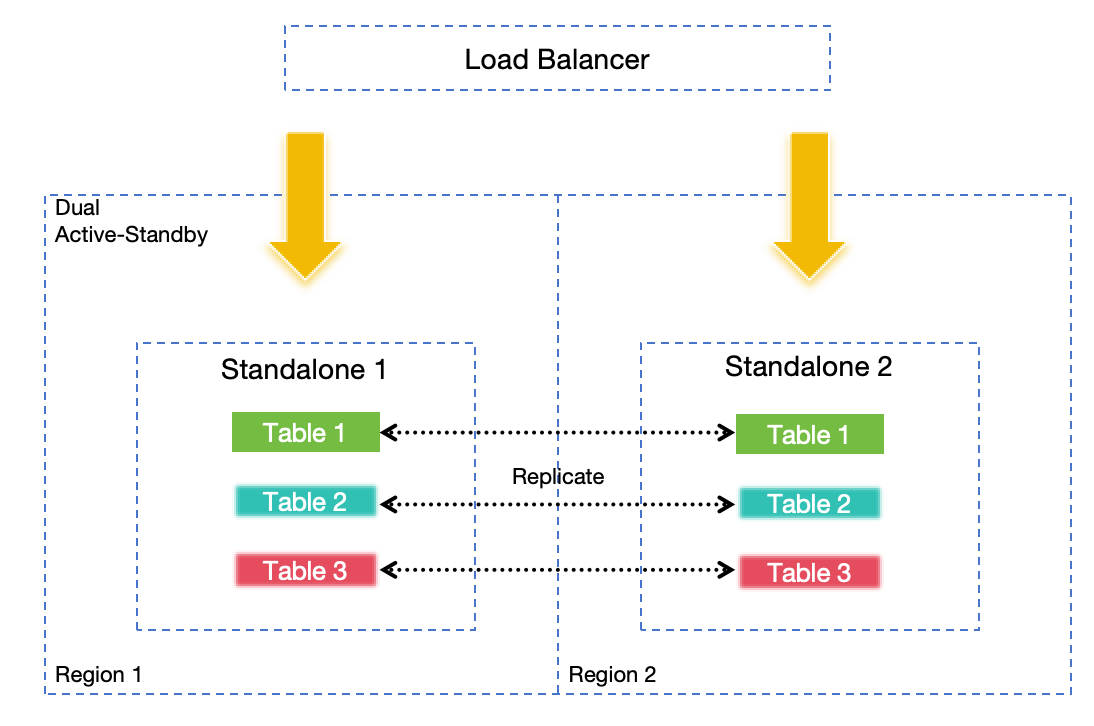
在某些边缘或中小型场景中,或者如果你没有资源部署远程 WAL 或对象存储,双活互备相对于 Standalone 的灾难恢复提供了更好的解决方案。 通过在两个独立节点之间同步复制请求,确保了高可用性。 即使使用基于本地磁盘的 WAL 和数据存储,任何单个节点的故障也不会导致数据丢失或服务可用性降低。
在不同区域部署节点也可以满足区域级灾难恢复要求,但可扩展性有限。
双活互备功能仅在 GreptimeDB 企业版中提供。
有关此解决方案的更多信息,请参阅基于双活-备份的 DR 解决方案。
基于单集群跨区域部署的 DR 解决方案
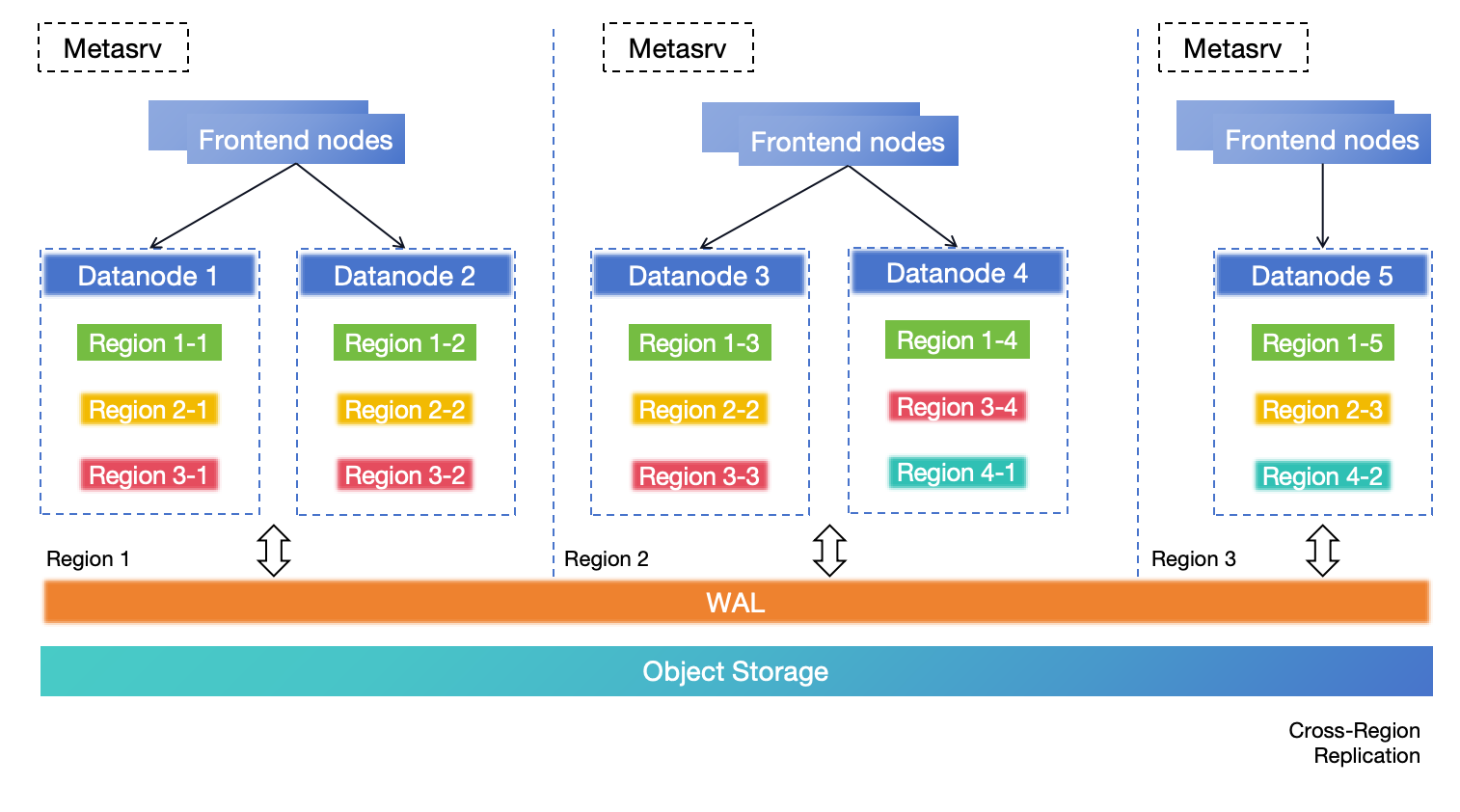
对于需要零 RPO 的中大型场景,强烈推荐此解决方案。 在此部署架构中,整个集群跨越三个 Region,每个 Region 都能处理读写请求。 两者都必须启用跨 Region DR 并使用远程 WAL 和对象存储实现数据复制。 如果 Region 1 因灾难而完全不可用,其中的表 Region 将在其他 Region 中打开和恢复。 Region 3 作为副本遵循 Metasrv 的多种协议。
此解决方案提供 Region 级别的容错、可扩展的写入能力、零 RPO 和分钟级或更低的 RTO。 有关此解决方案的更多信息,请参阅基于单集群跨区域部署的 DR 解决方案。
基于备份恢复的 DR 解决方案
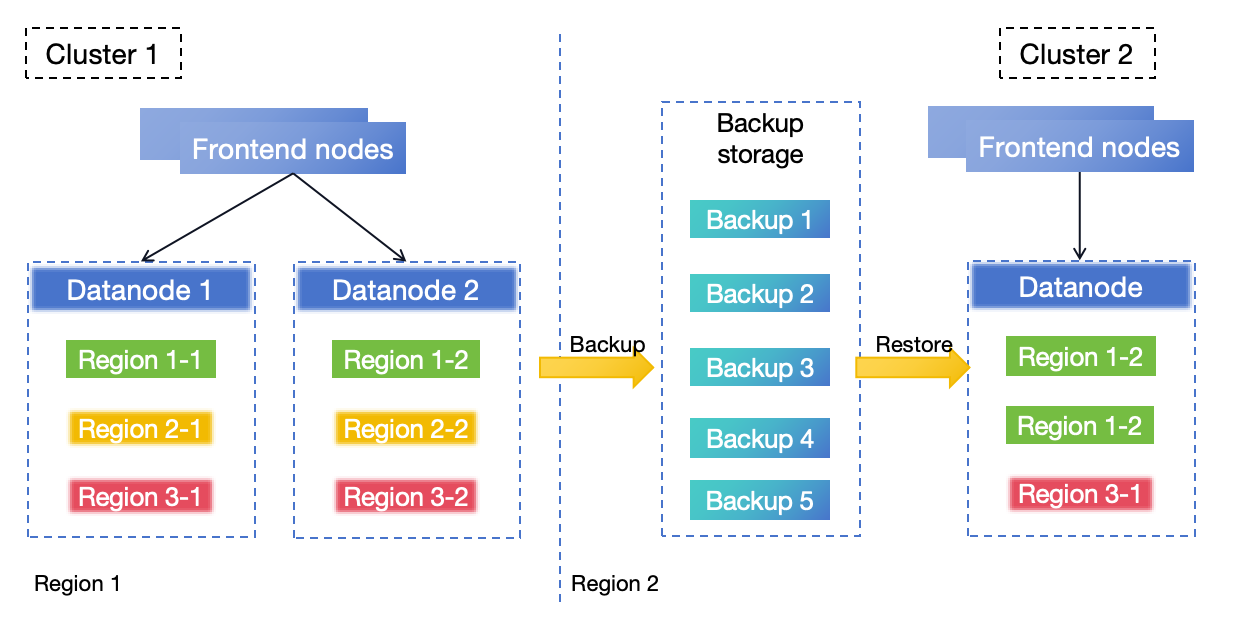
在此架构中,GreptimeDB Cluster 1 部署在 Region 1。 BR 进程持续定期将数据从 Cluster 1 备份到 Region 2。 如果 Region 1 遭遇灾难导致 Cluster 1 无法恢复, 你可以使用备份数据恢复 Region 2 中的新集群(Cluster 2)以恢复服务。
基于 BR 的 DR 解决方案提供的 RPO 取决于备份频率,RTO 随要恢复的数据大小而变化。
阅读备份与恢复数据获取详细信息,我们计划为此解决方案提供一种内部 BR 工具。
解决方案比较
通过比较这些 DR 解决方案,你可以根据其特定场景、需求和成本选择最终的选项。
| DR 解决方案 | 容错目标 | RPO | RTO | TCO | 场景 | 远程 WAL 和对象存储 | 备注 |
|---|---|---|---|---|---|---|---|
| 独立模式的 DR 解决方案 | 单区域 | 备份间隔 | 分钟或小时级 | 低 | 小型场景中对可用性和可靠性要求较低 | 可选 | |
| 基于双活-备份的 DR 解决方案 | 跨区域 | 0 | 分钟级 | �低 | 中小型场景中对可用性和可靠性要求较高 | 可选 | 商业功能 |
| 基于单集群跨区域部署的 DR 解决方案 | 多区域 | 0 | 分钟级 | 高 | 中大型场景中对可用性和可靠性要求较高 | 必需 | |
| 基于 BR 的 DR 解决方案 | 单区域 | 备份间隔 | 分钟或小时级 | 低 | 可接受的可用性和可靠性要求 | 可选 |