架构
在进行 GreptimeDB 的部署和管理之前,有必要了解其架构和关键组件。
组件
GreptimeDB 由三个关键组件组成 Metasrv、Frontend 和 Datanode。
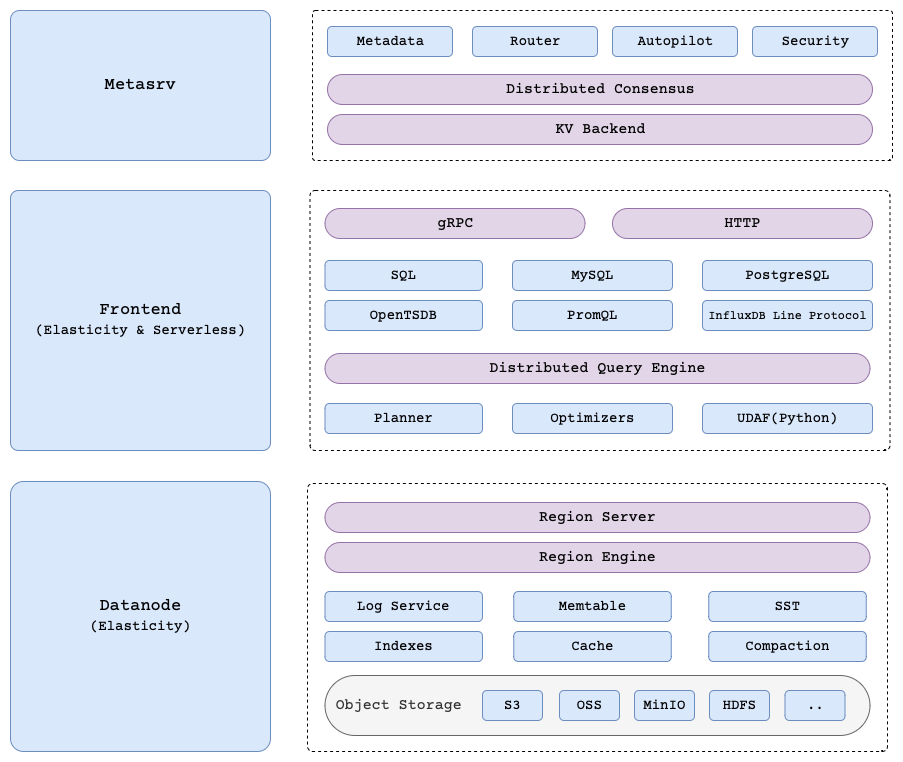
Metasrv(元数据服务器)
负责元数据存储和分布式调度, 协调 Frontend 和 Datanode 之间的操作。 Metasrv 存储集群的元数据信息, 包括表结构、Datanode 分布、每个表的 Region 分配等。
Frontend(前端服务)
作为无状态的代理服务,通过多种协议(如 SQL、PromQL、InfluxDB Line Protocol)为客户端提供读写服务。 Frontend 从 Metasrv 获取元数据并缓存在 catalog 中, 根据这些信息将请求转发到相应的 Datanode。
Datanode(数据节点)
负责数据的持久化存储和管理,支持多种存储后端, 如本地磁盘、S3、Azure Blob Storage 等。 每个 Datanode 可以服务多个 Region,并通过表引擎(存储引擎)决定数据的存储、管理和处理方式。
关键概念
- Region(数据分区):表中的一个连续数据段, 类似于传统关系型数据库中的分区概念。 Region 可以在多个 Datanode 上进行复制以提供高可用性, 其中任意副本都支持读请求, 但只有一个主副本支持写请求。
- 表引擎(Storage Engine):也被称为存储引擎。 决定数据在数据库中的存储、管理和处理方式的核心组件。 不同的引擎提供不同的功能特性、性能表现和权衡取舍。 有关更多信息,请参阅表引擎。
组件交互
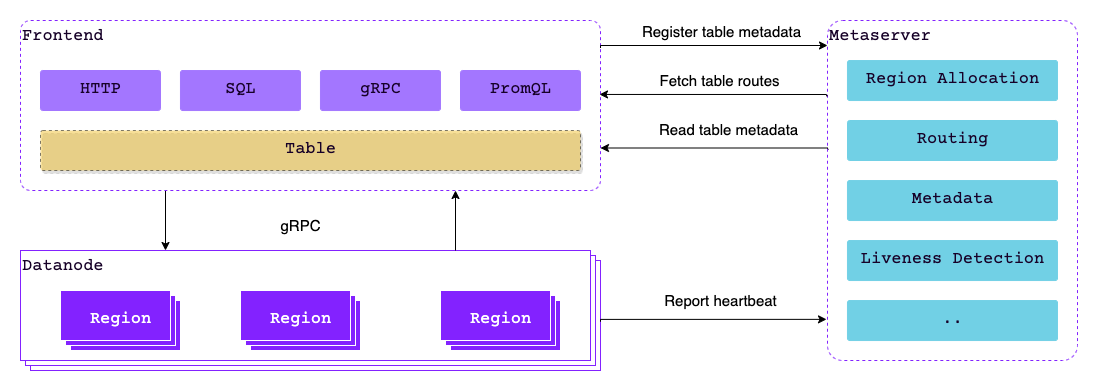
- 你可以通过各种协议与数据库交互,例如使用 InfluxDB line Protocol 插入数据,然后使用 SQL 或 PromQL 查询数据。Frontend 是客户端连接和操作数据库的组件,因此在其后面隐藏了 Datanode 和 Metasrv。
- 假设客户端向 Frontend 实例发送了 HTTP 请求来插入数据。当 Frontend 接收到请求时,它会使用相应的协议解析器解析请求正文,并从 Metasrv 的 catalog 中找到要写入的表。
- Frontend 依靠推拉结合的策略缓存来自 Metasrv 的元数据,因此它知道应将请求发送到哪个 Datanode,或者更准确地说,应该发送到哪个 Region。如果请求的内容需要存储在不同的 Region 中,则请求可能会被拆分并发送到多个 Region。
- 当 Datanode 接收到请求时,它将数据写入 Region 中,然后将响应发送回 Frontend。写入 Region 也意味着将数据写入底层的存储引擎中,该引擎最终将数据放置在持久化存储中。
- 当 Frontend 从目标 Datanode 接收到所有响应时,就会将结果返回给用户。
有关每个组件的更多详细信息,请参阅贡献者指南: