Query Engine
Introduction
GreptimeDB's query engine is built on Apache DataFusion (subproject under Apache Arrow), a brilliant query engine written in Rust. It provides a set of well functional components from logical plan, physical plan and the execution runtime. Below explains how each component is orchestrated and their positions during execution.
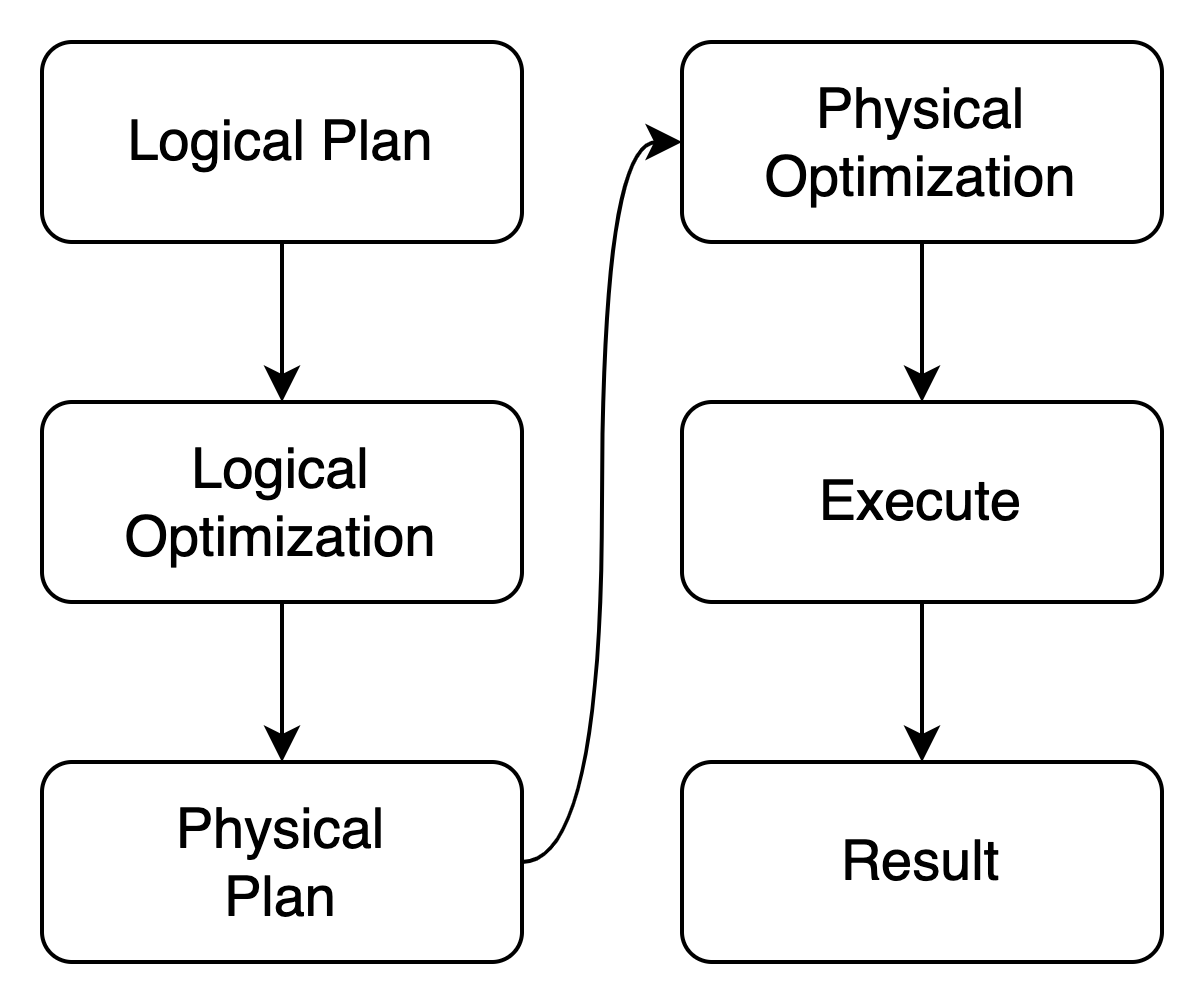
The entry point is the logical plan, which is used as the general intermediate representation of a query or execution logic etc. Two noticeable sources of logical plan are from: 1. the user query, like SQL through SQL parser and planner; 2. the Frontend's distributed query, which is explained in details in the following section.
Next is the physical plan, or the execution plan. Unlike the logical plan which is a big
enumeration containing all the logical plan variants (except the special extension plan node), the
physical plan is in fact a trait that defines a group of methods invoked during
execution. All data processing logics are packed in corresponding structures that
implement the trait. They are the actual operations performed on the data, like
aggregator MIN or AVG, and table scan SELECT ... FROM.
The optimization phase which improves execution performance by transforming both logical and physical plans, is now all based on rules. It is also called, "Rule Based Optimization". Some of the rules are DataFusion native and others are customized in Greptime DB. In the future, we plan to add more rules and leverage the data statistics for Cost Based Optimization/CBO.
The last phase "execute" is a verb, stands for the procedure that reads data from storage, performs calculations and generates the expected results. Although it's more abstract than previously mentioned concepts, you can just simply imagine it as executing a Rust async function. And it's indeed a future (stream).
EXPLAIN [VERBOSE] <SQL> is very useful if you want to see how your SQL is represented in the logical or physical plan.
Data Representation
GreptimeDB uses Apache Arrow as the in-memory data representation. It's column-oriented, in cross-platform format, and also contains many high-performance data operators. These features make it easy to share data in many different environments and implement calculation logic.
Indexing
In time series data, there are two important dimensions: timestamp and tag columns (or like primary key in a general relational database). GreptimeDB groups data in time buckets, so it's efficient to locate and extract data within the expected time range at a very low cost. The mainly used persistent file format Apache Parquet in GreptimeDB helps a lot -- it provides multi-level indices and filters that make it easy to prune data during querying. In the future, we will make more use of this feature, and develop our separated index to handle more complex use cases.
Distributed Execution
Covered in Distributed Querying.