Storage Engine
Introduction
The storage engine is responsible for storing the data of the database. Mito, based on LSMT (Log-structured Merge-tree), is the storage engine we use by default. We have made significant optimizations for handling time-series data scenarios, so mito engine is not suitable for general purposes.
Architecture
The picture below shows the architecture and process procedure of the storage engine.
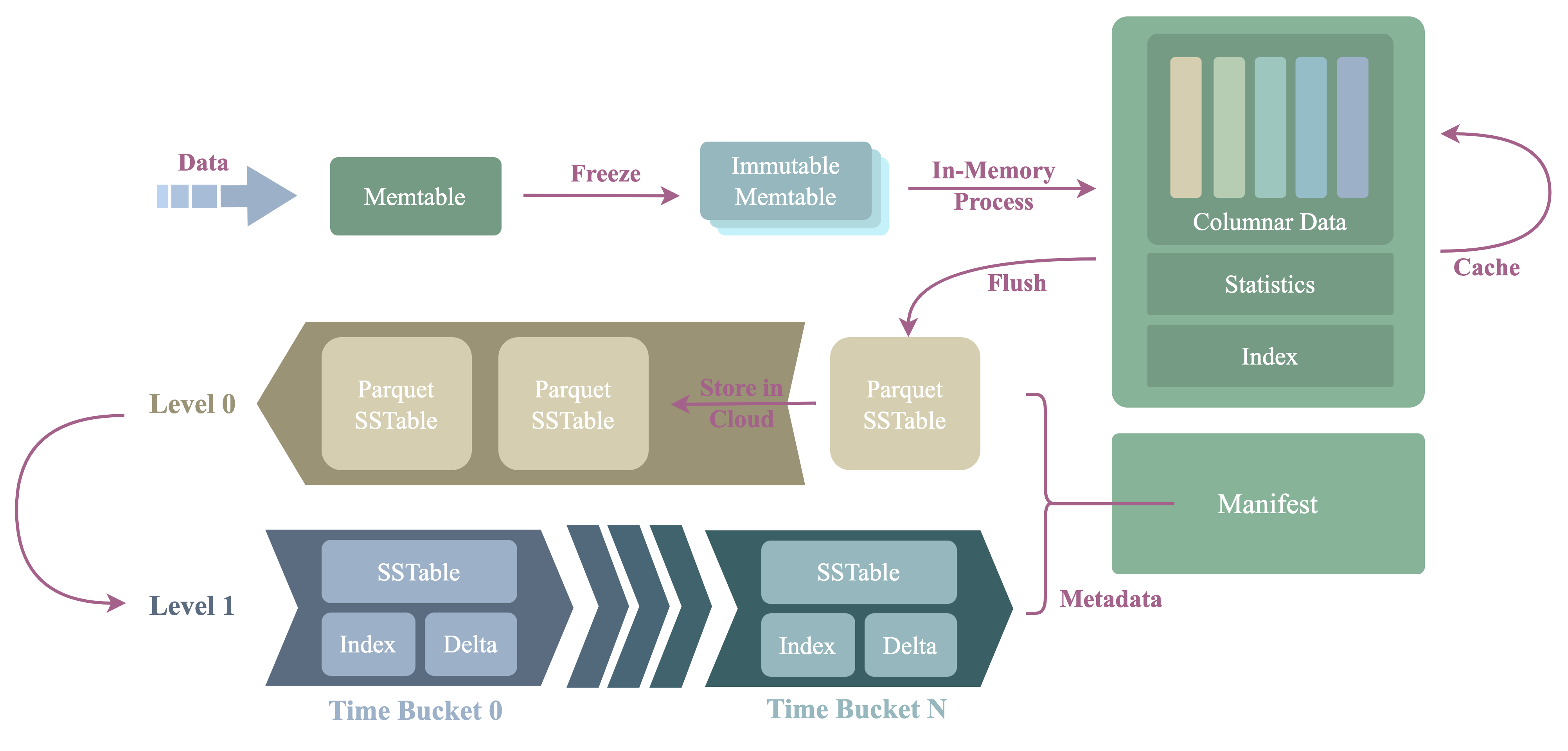
The architecture is the same as a traditional LSMT engine:
- WAL
- Guarantees high durability for data that is not yet being flushed.
- Based on the
Log StoreAPI, thus it doesn't care about the underlying storage media. - Log records of the WAL can be stored in the local disk, or a distributed log service which
implements the
Log StoreAPI.
- Memtables:
- Data is written into the
active memtable, akamutable memtablefirst. - When a
mutable memtableis full, it will be changed to aread-only memtable, akaimmutable memtable.
- Data is written into the
- SST
- The full name of SST, aka SSTable is
Sorted String Table. Immutable memtableis flushed to persistent storage and produces an SST file.
- The full name of SST, aka SSTable is
- Compactor
- Small
SSTis merged into largeSSTby the compactor via compaction. - The default compaction strategy is TWCS.
- Small
- Manifest
- The manifest stores the metadata of the engine, such as the metadata of the
SST.
- The manifest stores the metadata of the engine, such as the metadata of the
- Cache
- Speed up queries.
Data Model
The data model provided by the storage engine is between the key-value model and the tabular model.
tag-1, ..., tag-m, timestamp -> field-1, ..., field-n
Each row of data contains multiple tag columns, one timestamp column, and multiple field columns.
0 ~ mtag columns- Tag columns can be nullable.
- Specified during table creation using
PRIMARY KEY.
- Must include one timestamp column
- Timestamp column cannot be null.
- Specified during table creation using
TIME INDEX.
0 ~ nfield columns- Field columns can be nullable.
- Data is sorted by tag columns and timestamp column.
Region
Data in the storage engine is stored in regions, which are logical isolated storage units within the engine. Rows within a region must have the same schema, which defines the tag columns, timestamp column, and field columns within the region. The data of tables in the database is stored in one or multiple regions.