Distributed Querying
Most steps of querying in frontend and datanode are identical. The only difference is that Frontend have a "special" step in planning phase to make the logical query plan distributed. Let's reference it as "dist planner" in the following text.
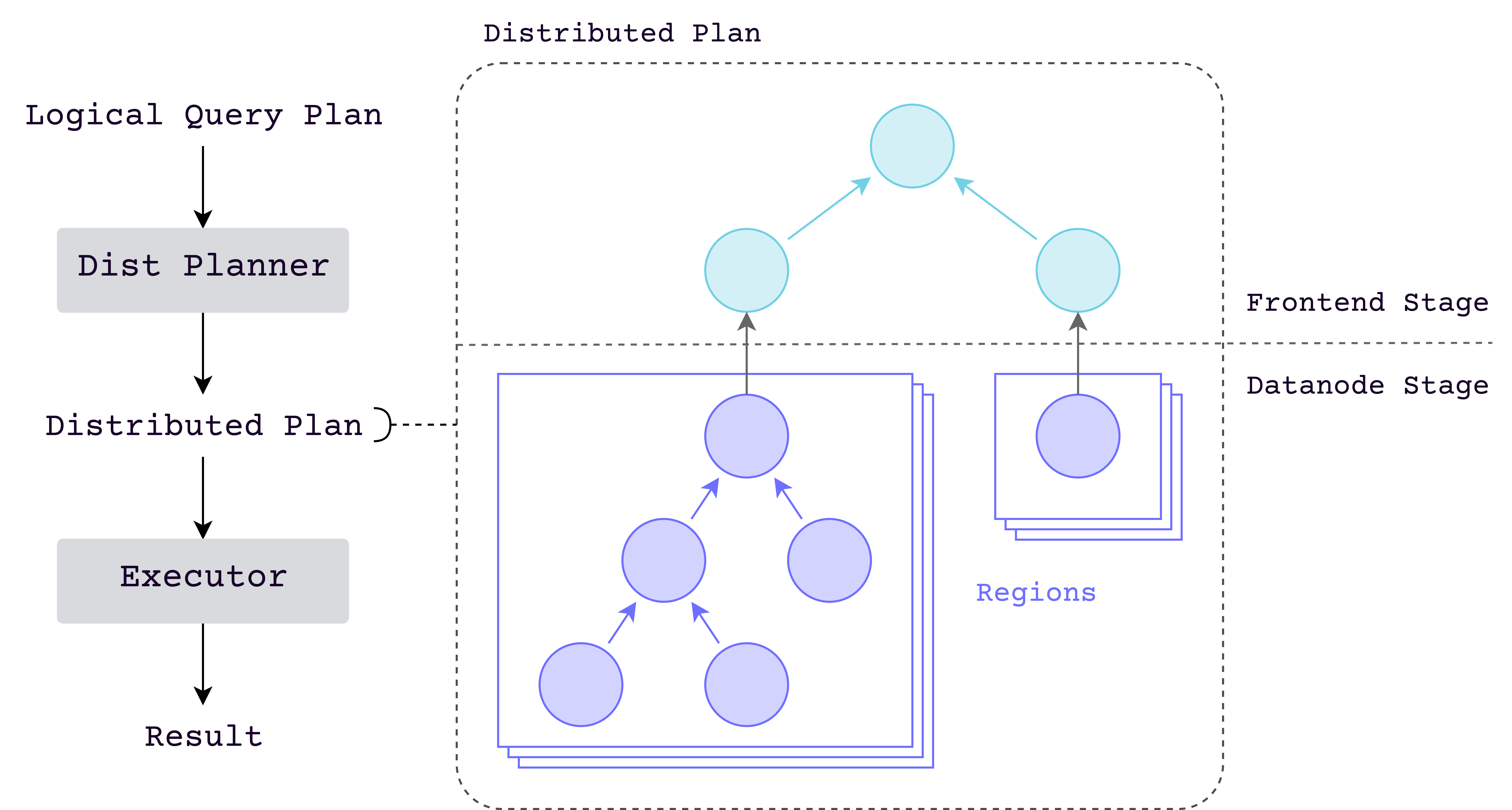
The modified, distributed logical plan has multiple stages, each of them is executed in different server node.
Dist Planner
Planner will traverse the input logical plan, and split it into multiple stages by the "commutativity rule".
This rule is under heavy development. At present it will consider things like:
- whether the operator itself is commutative
- how the partition rule is configured
- etc...
Dist Plan
Except the first stage, which have to read data from files in storage. All other stages' leaf node are actually a gRPC call to its previous stage.
Sub-plan in a stage is itself a complete logical plan, and can be executed independently without the follow up stages. The plan is encoded in substrait format.