Overview
Read Replica is a key feature in GreptimeDB's Enterprise Cluster Edition, designed to enhance the overall read-write performance and scalability of the database system.
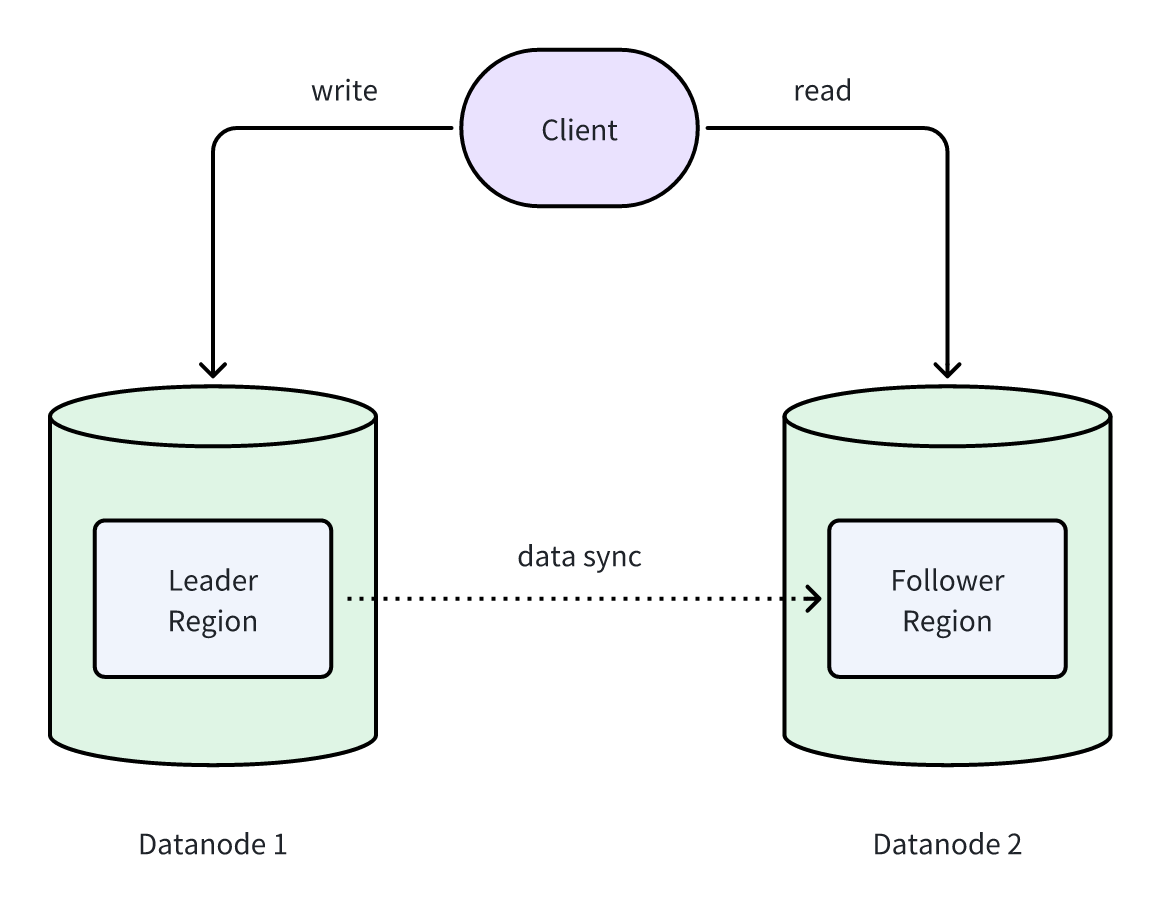
In the Read Replica mechanism, clients write data to the Leader Region (write replica), which then synchronizes the data to Follower Regions (read replicas). Follower Regions serve as read-only replicas of the Leader Region. By configuring Datanode groups, Leader Regions and Follower Regions can be deployed on different Datanode nodes, read and write requests are effectively isolated, preventing resource contention and delivering a smoother experience:
Principles
GreptimeDB's Enterprise Cluster Edition leverages its architecture to enable near-zero-cost data synchronization between replicas. Additionally, Read Replicas can access newly written data with minimal latency. Below is a brief explanation of the data synchronization and read mechanisms.
Data Synchronization
In GreptimeDB, storage and compute resources are disaggregated. All data is stored in SST files on object storage. Thus, synchronizing data between Leader and Follower Regions does not require copying SST files -- only their metadata needs to be synced. Metadata is significantly smaller than SST files, making synchronization effortless. Once metadata is synced, the Read Replica "possesses" the same SST files and can access the data:
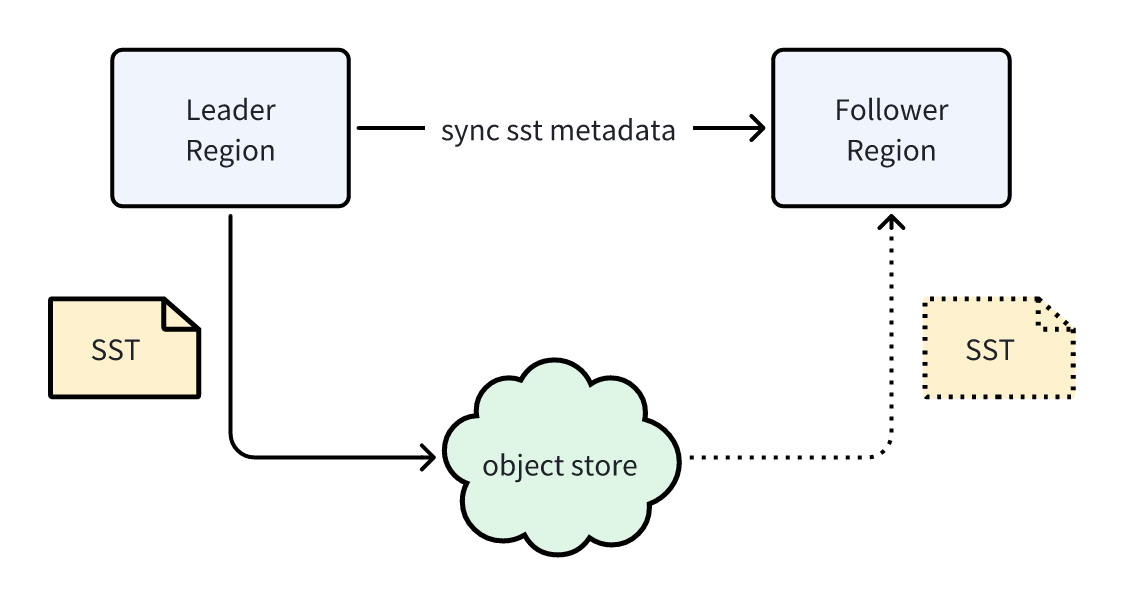
In practice, SST files metadata is persisted in a special manifest file, also stored in object storage. Each manifest file has a unique version number. Synchronizing metadata between Leader and Follower Regions essentially involves syncing this version number -- a simple integer, ensuring minimal overhead. After receiving the version number, the Follower Region fetches the manifest file from object storage, thereby obtaining the SST files metadata generated by the Leader Region.
The manifest version number is synchronized via heartbeats between Regions and Metasrv. The Leader Region includes the version number in its heartbeat to Metasrv, which then forwards it to Follower Regions in their heartbeat responses:
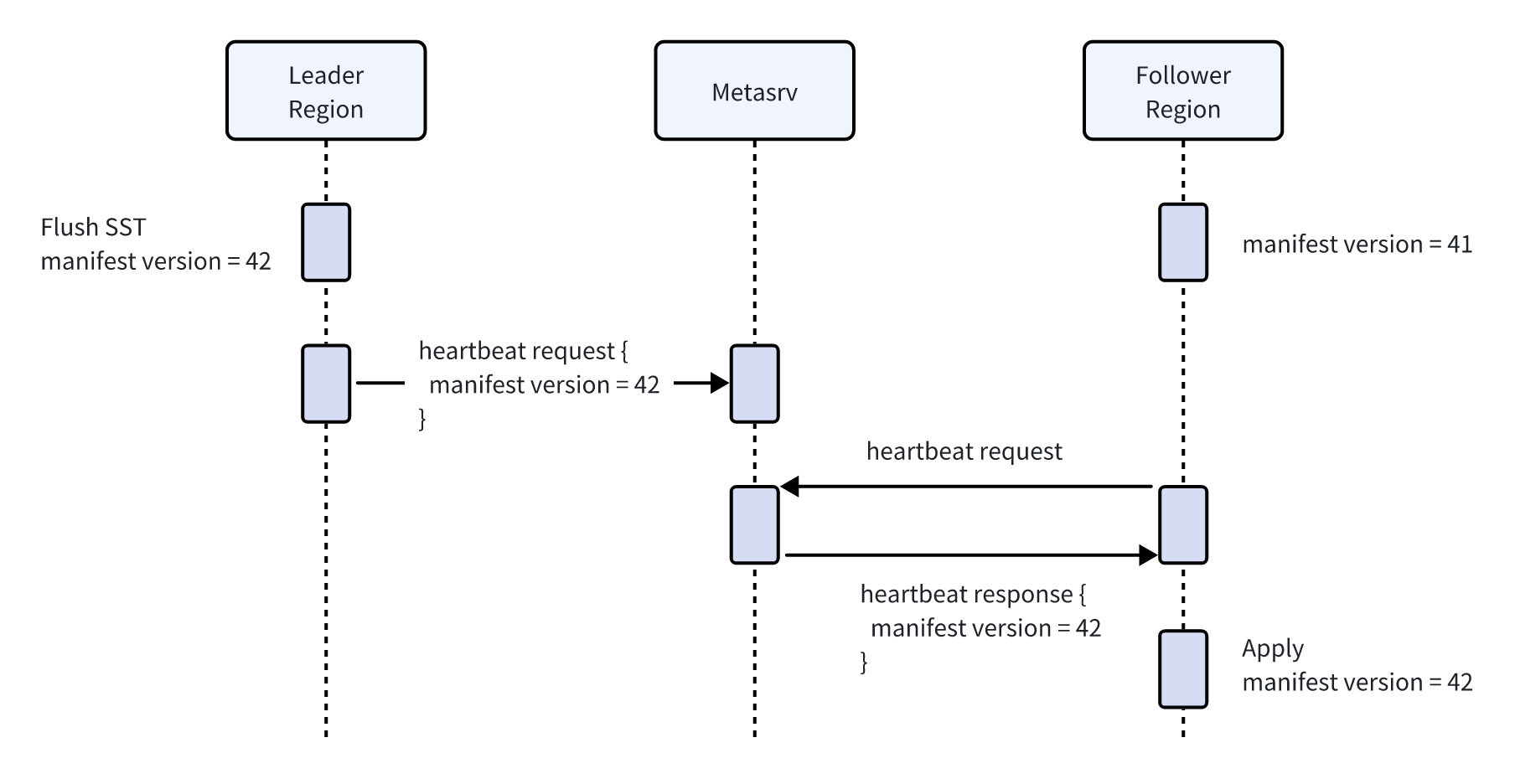
It's easy to see, if there were only SST files synchronization mechanism in place, the delay for Read Replica to access written data would be the sum of the heartbeat intervals between Leader/Follower Regions and Metasrv. For example, with a default 3-second heartbeat interval, Read Replica would only see the data that are written to SST files and flushed to object store 3 to 6 seconds prior. While this suffices for clients with relaxed freshness requirements, additional mechanisms are needed for near-real-time reads.
Data Read
Newly written data are stored in the Leader Region’s memtable. To access the latest data, Follower Region needs to request the memtable data from the Leader Region. By combining this with SST files data (obtained via data sync above), the Follower Region provides clients with a complete dataset, including the most recent writes:
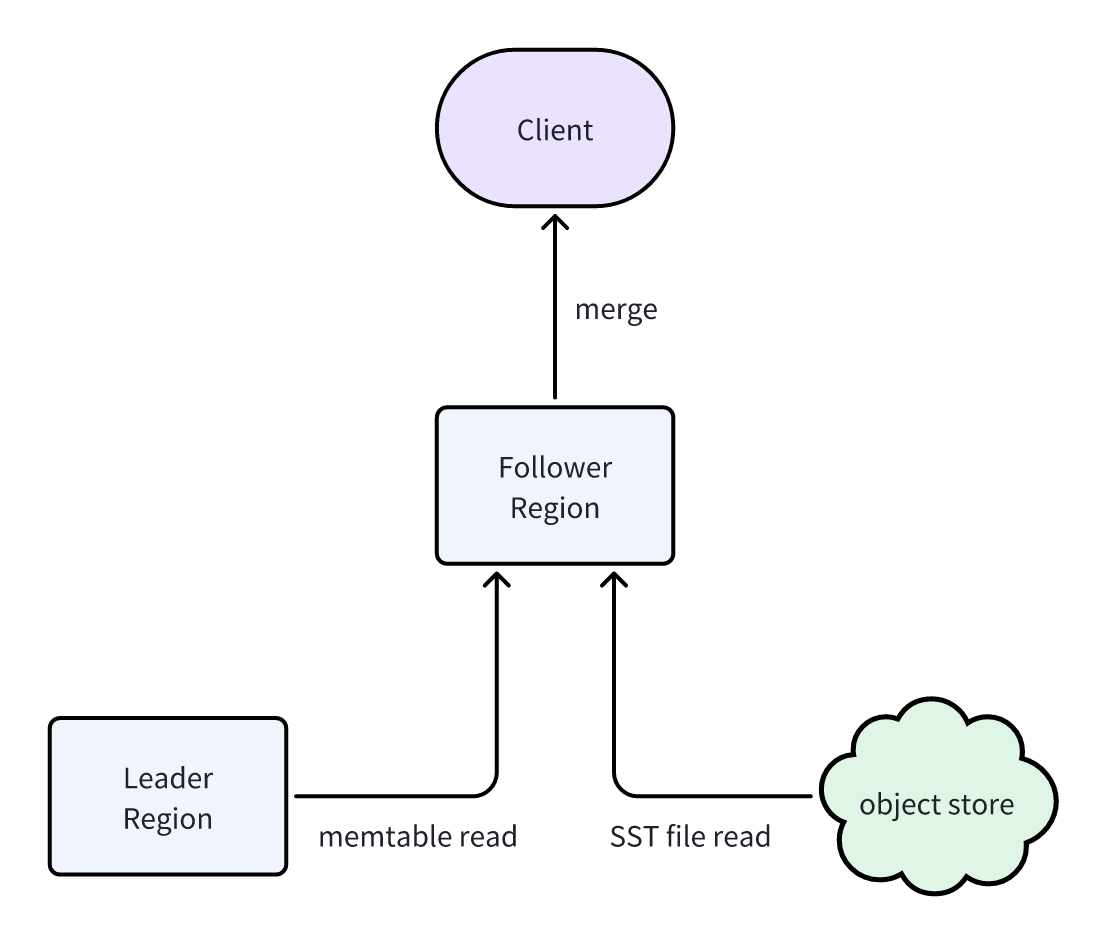
Follower Region fetch memtable data from Leader Region via an internal gRPC interface. While this imposes some read load on the Leader Region, the impact is minimal since the memtable data resides in memory and is finite in size.