Architecture
Before diving into the deployment and administration of GreptimeDB, it's important to understand its architecture and key components.
Components
GreptimeDB consists of three key components: Metasrv, Frontend, and Datanode.
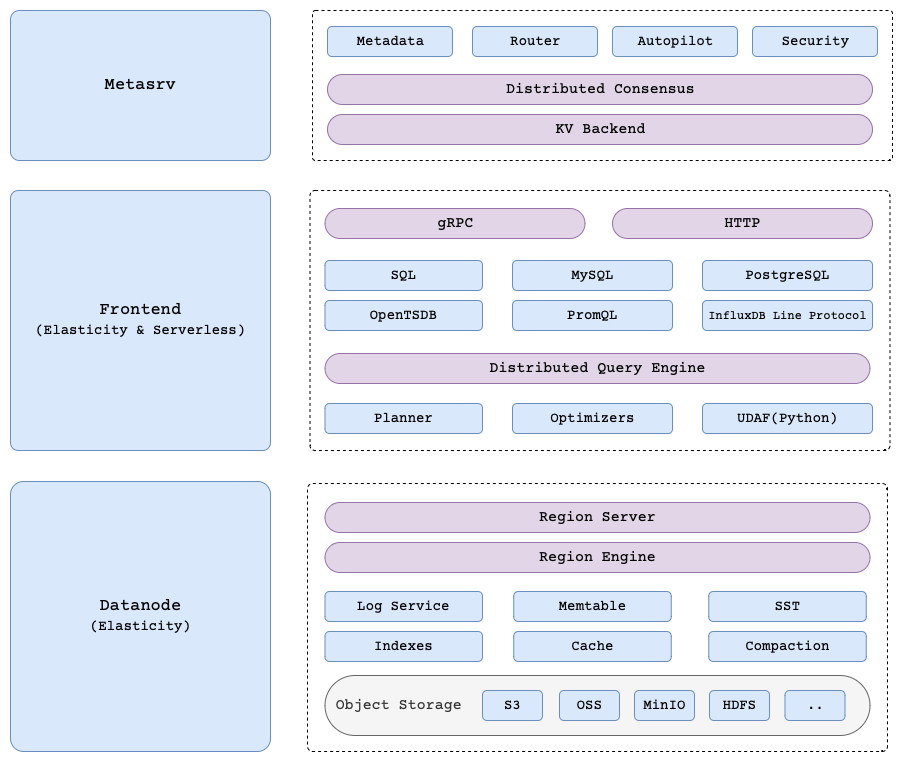
Metasrv
Metasrv coordinates operations between Frontend and Datanode components, stores cluster metadata including tables, datanodes, and region mappings, and provides metadata services to Frontend instances.
Frontend
Frontend is a stateless service that serves client requests via multiple protocols, acting as a proxy that forwards read/write requests to appropriate Datanodes. It maintains a catalog that maps tables to regions and their corresponding Datanodes, caching metadata from Metasrv for efficient request routing.
Datanode
Datanode is responsible for persistent data storage to local disk or cloud storage services like AWS S3 and Azure Blob Storage, serves multiple regions to Frontend instances, and handles all data storage and retrieval operations within the distributed system.
Key Concepts
- Region: A contiguous segment of a table, similar to a partition in relational databases. Regions can be replicated across multiple Datanodes, with one writable replica for writes and any replica serving reads.
- Table Engines: Also called storage engines. Determine how data is stored, managed, and processed. Different engines offer varying performance characteristics and trade-offs. See Table Engines for details.
How it works
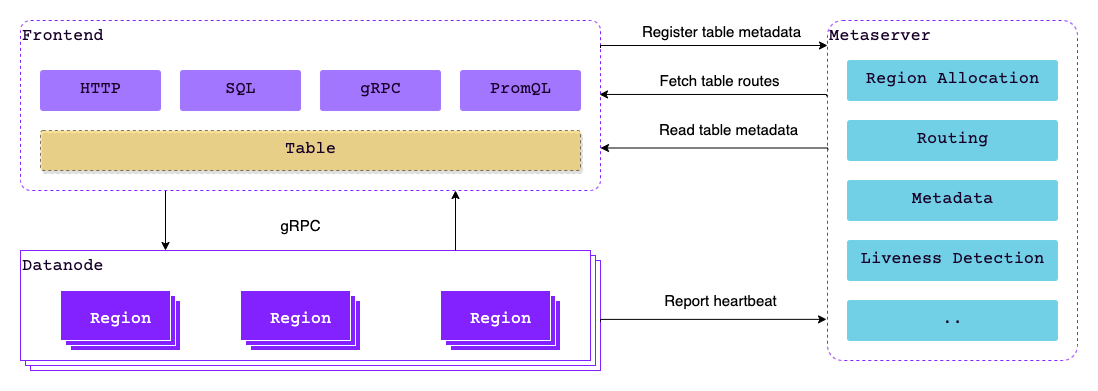
- You can interact with the database via various protocols, such as ingesting data using InfluxDB line protocol, then exploring the data using SQL or PromQL. The Frontend is the component that clients connect to and operate, thus hide Datanode and Metasrv behind it.
- Assumes a user uses the HTTP API to insert data into the database, by sending a HTTP request to a Frontend instance. When the Frontend receives the request, it then parses the request body using corresponding protocol parser, and finds the table to write to from a catalog manager based on Metasrv.
- The Frontend relies on a push-pull strategy to cache metadata from Metasrv, thus it knows which Datanode, or more precisely, the Region a request should be sent to. A request may be split and sent to multiple Regions, if its contents need to be stored in different Regions.
- When Datanode receives the request, it writes the data to the Region, and then sends response back to the Frontend. Writing to the Region will then write to the underlying storage engine, which will eventually put the data to persistent device.
- Once Frontend has received all responses from the target Datanodes, it then sends the result back to the user.
For more details on each component, see the contributor guides: