Migrate from PostgreSQL
This document will guide you through the migration process from PostgreSQL to GreptimeDB.
Before you start the migration
Please be aware that though GreptimeDB supports the wire protocol of PostgreSQL, it does not mean GreptimeDB implements all PostgreSQL's features. You may refer to:
- The ANSI Compatibility to see the constraints regarding using SQL in GreptimeDB.
- The Data Modeling Guide to create proper table schemas.
- The Data Index Guide for index planning.
Migration steps
Create the databases and tables in GreptimeDB
Before migrating the data from PostgreSQL, you first need to create the corresponding databases and tables in GreptimeDB. GreptimeDB has its own SQL syntax for creating tables, so you cannot directly reuse the table creation SQLs that are produced by PostgreSQL.
When you write the table creation SQL for GreptimeDB, it's important to understand its "data model" first. Then, please take the following considerations in your create table SQL:
-
Since the time index column cannot be changed after the table is created, you need to choose the time index column carefully. The time index is best set to the natural timestamp when the data is generated, as it provides the most intuitive way to query the data, and the best query performance. For example, in the IOT scenes, you can use the collection time of sensor data as the time index; or the occurrence time of an event in the observability scenes.
-
In this migration process, it's not recommend to create another synthetic timestamp, such as a new column created with
DEFAULT current_timestamp()as the time index column. It's not recommend to use the random timestamp as the time index either. -
It's vital to set the most fit timestamp precision for your time index column, too. Like the chosen of time index column, the precision of it cannot be changed as well. Find the most fit timestamp type for your data set here.
-
Choose a primary key only when it is truly needed. The primary key in GreptimeDB is different from that in PostgreSQL. You should use a primary key only when:
- Most queries can benefit from the ordering.
- You need to deduplicate (including delete) rows by the primary key and time index.
Otherwise, setting a primary key is optional and it may hurt performance. Read Primary Key for details.
Finally please refer to "CREATE" SQL document for more details for choosing the right data types and "ttl" or "compaction" options, etc.
-
Choose proper indexes to speed up queries.
- Inverted index: is ideal for filtering by low-cardinality columns and quickly finding rows with specific values.
- Skipping index: works well with sparse data.
- Fulltext index: enables efficient keyword and pattern search in large text columns.
For details and best practices, refer to the data index documentation.
Write data to both GreptimeDB and PostgreSQL simultaneously
Writing data to both GreptimeDB and PostgreSQL simultaneously is a practical strategy to avoid data loss during migration. By utilizing PostgreSQL's client libraries (JDBC + a PostgreSQL driver), you can set up two client instances - one for GreptimeDB and another for PostgreSQL. For guidance on writing data to GreptimeDB using SQL, please refer to the Ingest Data section.
If retaining all historical data isn't necessary, you can simultaneously write data to both GreptimeDB and PostgreSQL for a specific period to accumulate the required recent data. Subsequently, cease writing to PostgreSQL and continue exclusively with GreptimeDB. If a complete migration of all historical data is needed, please proceed with the following steps.
Export data from PostgreSQL
pg_dump is a commonly used tool to export data from
PostgreSQL. Using it, we can export the data that can be later imported into GreptimeDB directly. For example, if we
want to export schemas whose names start with db in the database postgres from PostgreSQL, we can use the following
command:
pg_dump -h127.0.0.1 -p5432 -Upostgres -ax --column-inserts --no-comments -n 'db*' postgres | grep -v "^SE" > /path/to/output.sql
Replace the -h, -p and -U flags with the appropriate values for your PostgreSQL server. The -n flag is used to
specify the schemas to be exported. And the database postgres is at the end of the pg_dump command line. Note that we pipe the pg_dump output through a special
grep, to remove some unnecessary SET or SELECT lines. The final output will be written to the
/path/to/output.sql file.
The content in the /path/to/output.sql file should be like this:
~ ❯ cat /path/to/output.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 16.4 (Debian 16.4-1.pgdg120+1)
-- Dumped by pg_dump version 16.4
--
-- Data for Name: foo; Type: TABLE DATA; Schema: db1; Owner: postgres
--
INSERT INTO db1.foo (ts, a) VALUES ('2024-10-31 00:00:00', 1);
INSERT INTO db1.foo (ts, a) VALUES ('2024-10-31 00:00:01', 2);
INSERT INTO db1.foo (ts, a) VALUES ('2024-10-31 00:00:01', 3);
INSERT INTO ...
--
-- Data for Name: foo; Type: TABLE DATA; Schema: db2; Owner: postgres
--
INSERT INTO db2.foo (ts, b) VALUES ('2024-10-31 00:00:00', '1');
INSERT INTO db2.foo (ts, b) VALUES ('2024-10-31 00:00:01', '2');
INSERT INTO db2.foo (ts, b) VALUES ('2024-10-31 00:00:01', '3');
INSERT INTO ...
--
-- PostgreSQL database dump complete
--
Import data into GreptimeDB
The psql -- PostgreSQL interactive terminal can be used to
import data into GreptimeDB. Continuing the above example, say the data is exported to file /path/to/output.sql, then
we can use the following command to import the data into GreptimeDB:
psql -h127.0.0.1 -p4003 -d public -f /path/to/output.sql
Replace the -h and -p flags with the appropriate values for your GreptimeDB server. The -d of the psql command is used to specify the database and cannot be omitted. The value public of -d is the default database used by GreptimeDB. You can also add -a to the end to see every
executed line, or -s for entering the single-step mode.
To summarize, data migration steps can be illustrate as follows:
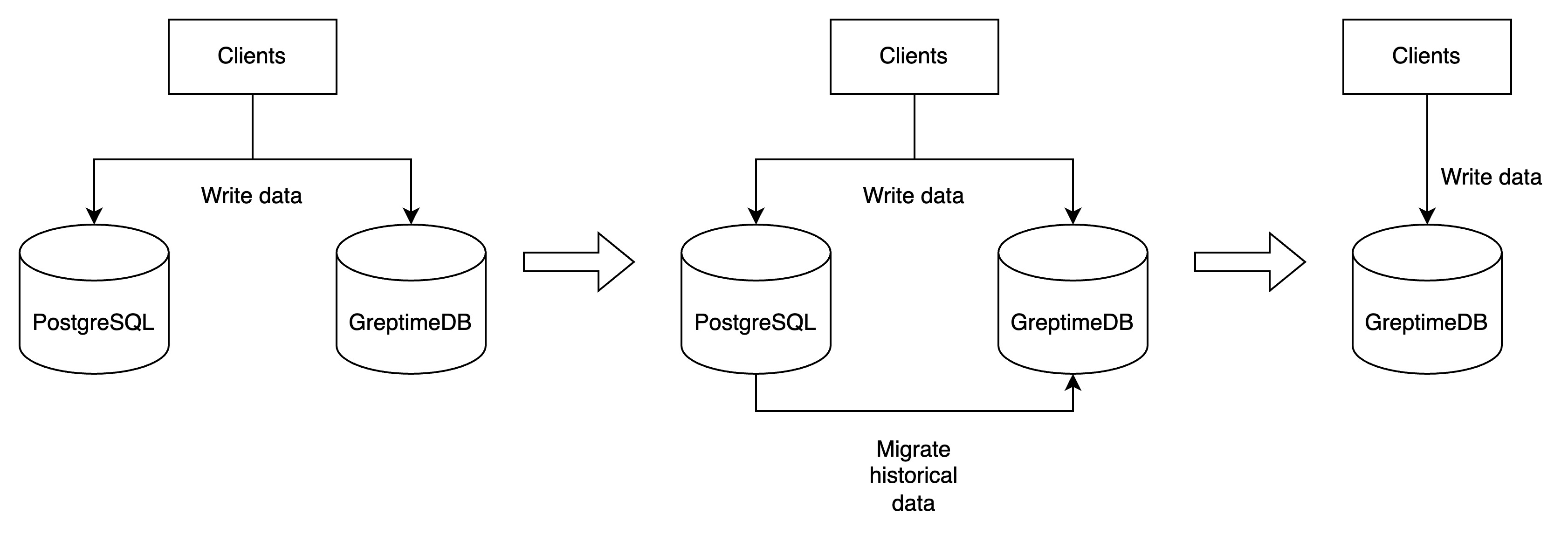
After the data migration is completed, you can stop writing data to PostgreSQL and continue using GreptimeDB exclusively!
If you need a more detailed migration plan or example scripts, please provide the specific table structure and data volume. The GreptimeDB official community will offer further support. Welcome to join the Greptime Slack.