DR Solution Based on Active-Active Failover
Active-Active Failover is only available in GreptimeDB Enterprise.
RPO
In GreptimeDB's "Active-Active Failover" architecture, there are two nodes. Both nodes can provide the ability to execute reads and writes from clients. However, to achieve the goals of the RTO and RPO, we need to do some configurations about them. First of all, let me introduce the modes to reads and writes.
For reads:
SingleRead: a read operation is executed in one node only, and the results are returned to the client directly.DualRead: a read operation is executed in both nodes. The results are merged and deduplicated before returning to the client.
The following picture illustrates the difference between the two read modes:
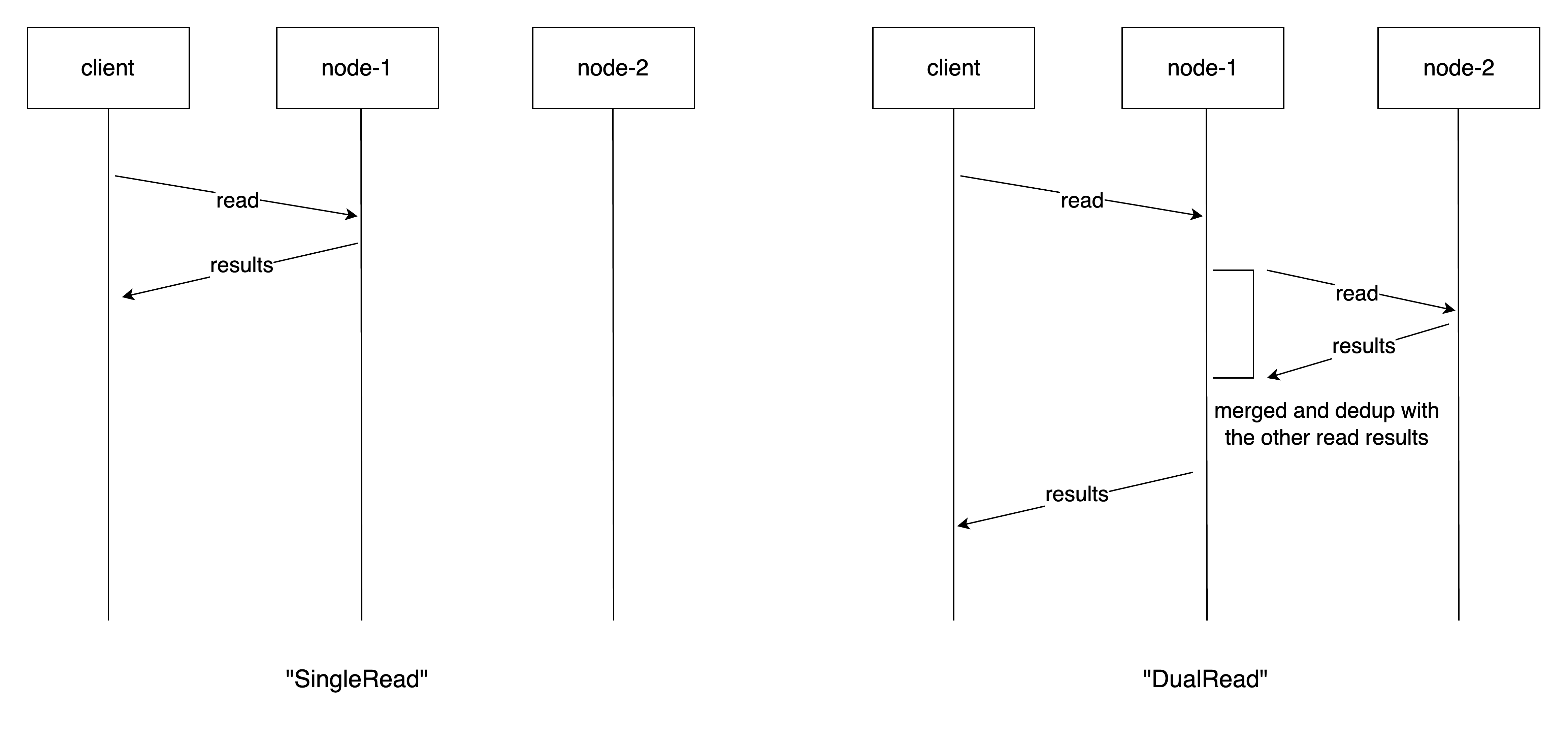
For writes:
SyncWrite: a write operation is executed in both nodes, and is considered success only if it is succeeded in both nodes before returning to the clients.AsyncWrite: a write operation is still executed in both nodes, but the result is returned to the clients when it is done on the issued node. The other node will receive a copy of the write operation from the issued node, asynchronously.
The following picture illustrates the difference between the two write modes:
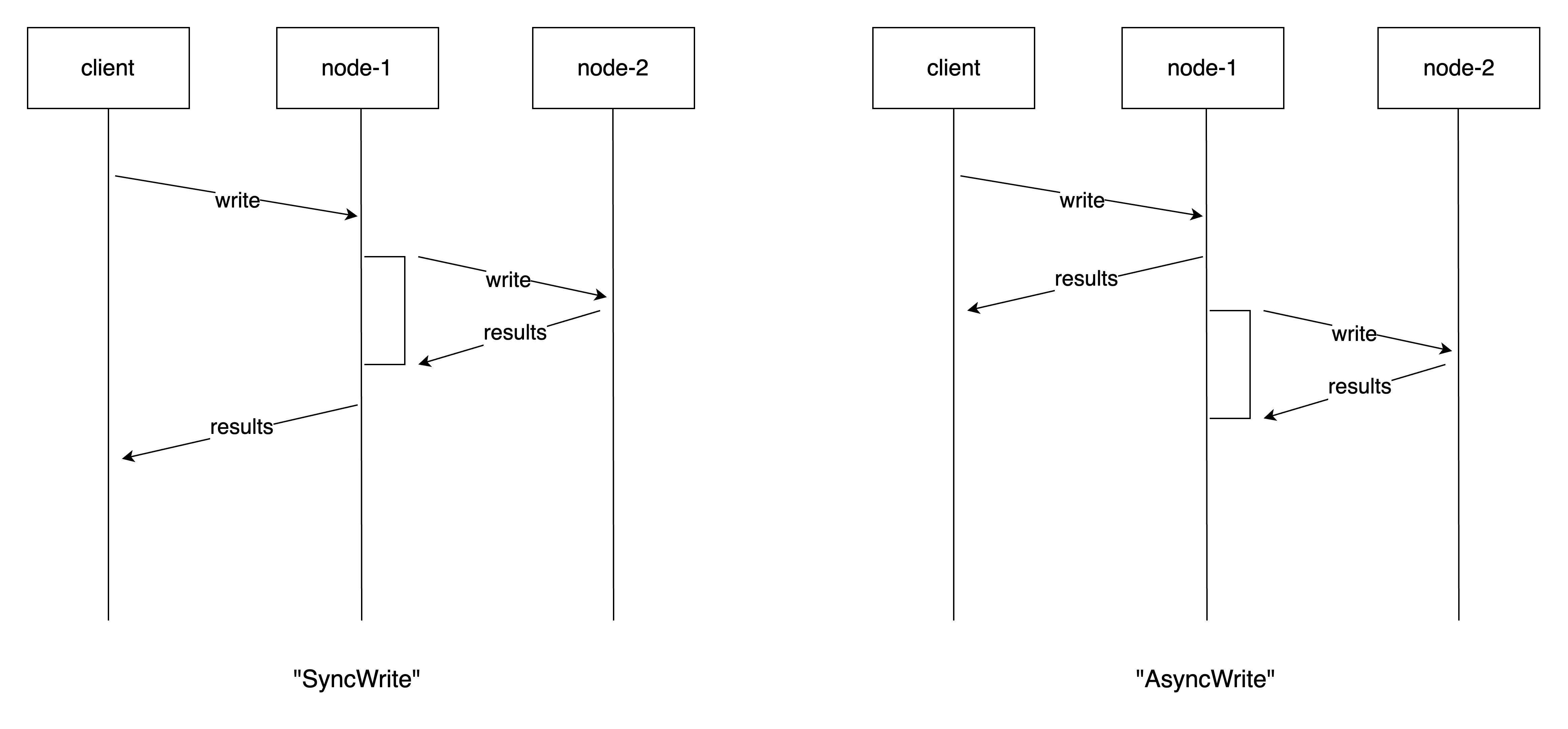
So there are four combinations on reads and writes, and their RPOs are:
| RPO | SingleRead | DualRead |
|---|---|---|
SyncWrite | 0 | 0 |
AsyncWrite | network latency between two nodes | 0 |
Since the writes are synchronized between the two nodes in SyncWrite mode, the RPO is always zero regardless what read mode is. However, SyncWrite requires both nodes functioned well simultaneously to handle writes. If your workload is write-light-read-heavy, and can tolerate some system unavailable time to bring back the healthiness of both nodes when the disaster happened, we recommend the SyncWrite + SingleRead combination.
Another combination that can achieve 0 RPO is AsyncWrite + DualRead. It's the opposite of the said above, suitable for the workload of write-heavy-read-light, and the restriction of the system availability can be relaxed.
The final combination is AsyncWrite + SingleRead. This is the most relaxed setup. If the network between the nodes is good, and the nodes are hosted reliably, for example, the two nodes are hosted in a virtual machine system inside one AZ (Available Zone, or "Data Center"), you may prefer this combination. Of course, just remember that the RPO is not zero.
RTO
To retain the minimality of requirements of our active-active architecture, we don't have a third node or a third service to handle the failover of GreptimeDB. Generally speaking, there are several ways to handle the failover:
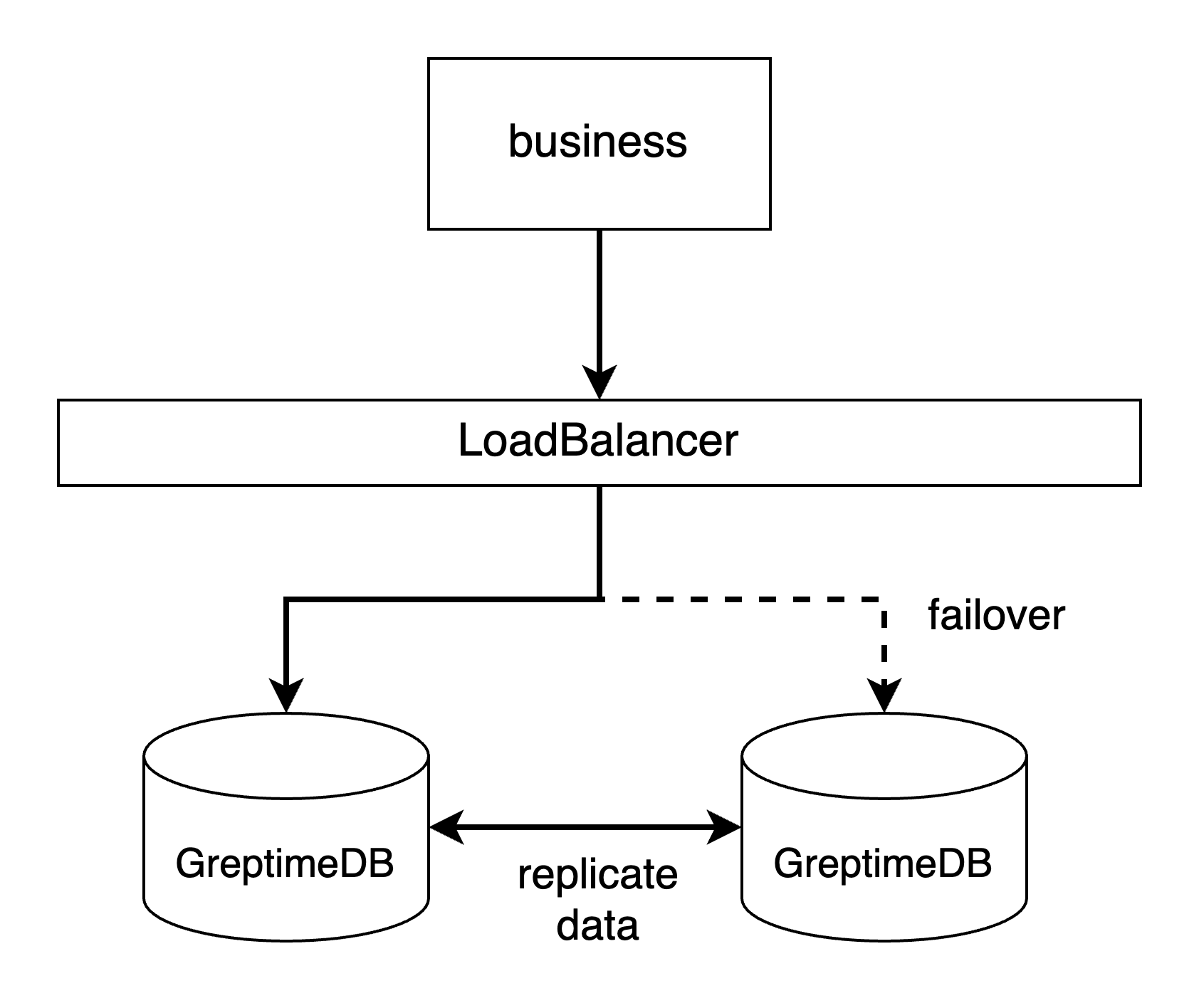
- Through a LoadBalancer. If you can spare another node for deploying a LoadBalancer like the Nginx, or if you have your own LoadBalance service can be used, we recommend this way.
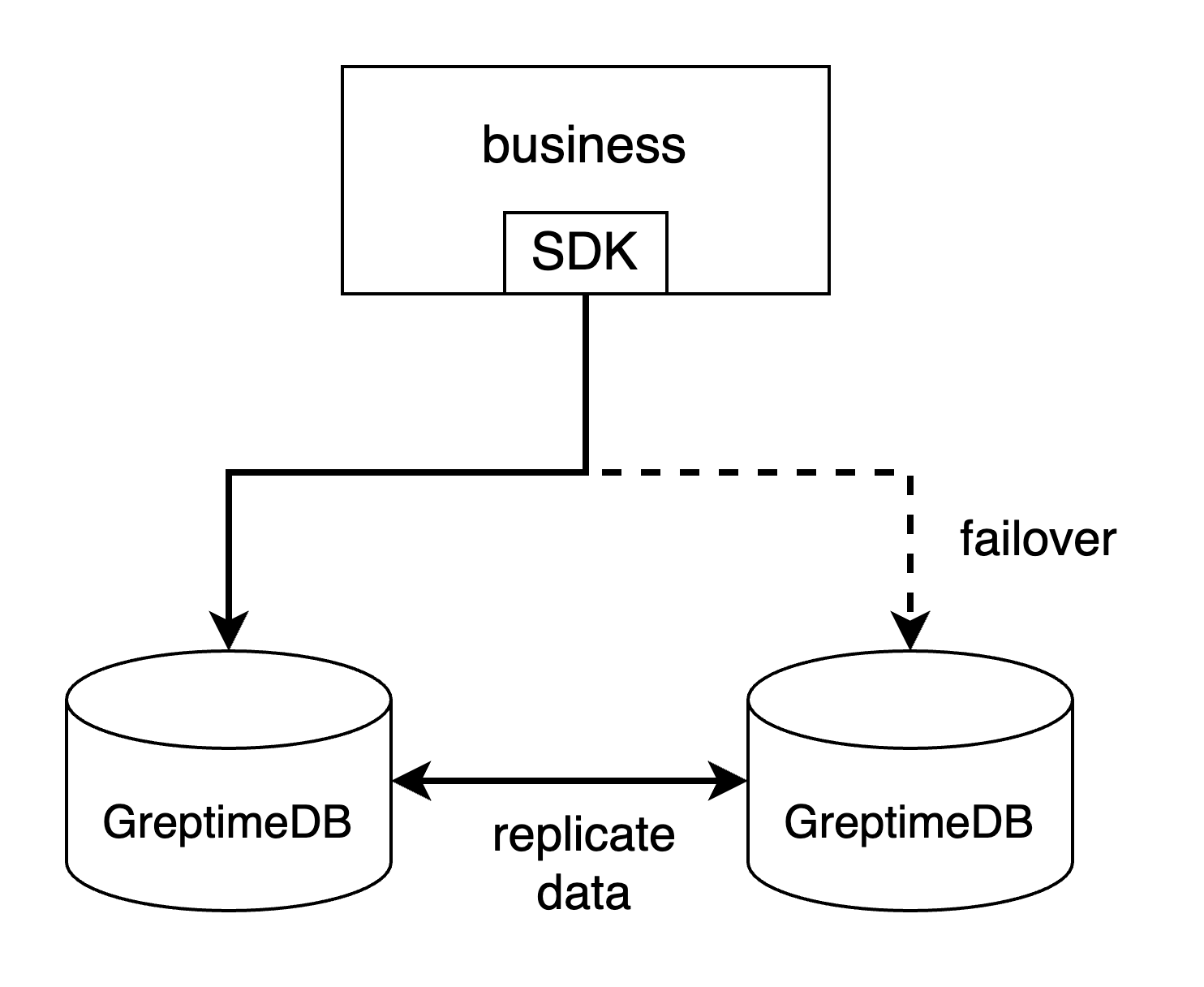
- By client SDK's failover mechanism. For example, if you are using MySQL Connector/j, you can configure the failover by setting multiple hosts and ports in the connection URL (see its document here). PostgreSQL's driver has the same mechanism. This is the most easy way to handle the failover, but not every client SDK supports this failover mechanism.
- Custom endpoint update mechanism. If you can detect the fall of nodes, you can retroactively update the GreptimeDB's endpoint set in your code.
To compare the RPO and RTO across different disaster recovery solutions, please refer to "Solution Comparison".
Summary
You can choose different read/write modes combination to achieve your goal for RPO. This is inherent to GreptimeDB active-active architecture. As to RTO, we rely on external efforts to handle the failover. A LoadBalancer is best suited for this job.