Disaster Recovery
GreptimeDB is a distributed database designed to withstand disasters. It provides different solutions for disaster recovery (DR).
This document contains:
- Basic concepts in DR.
- The deployment architecture of GreptimeDB and Backup & Restore (BR).
- GreptimeDB provides the DR solutions.
- Compares these DR solutions.
Basic Concepts
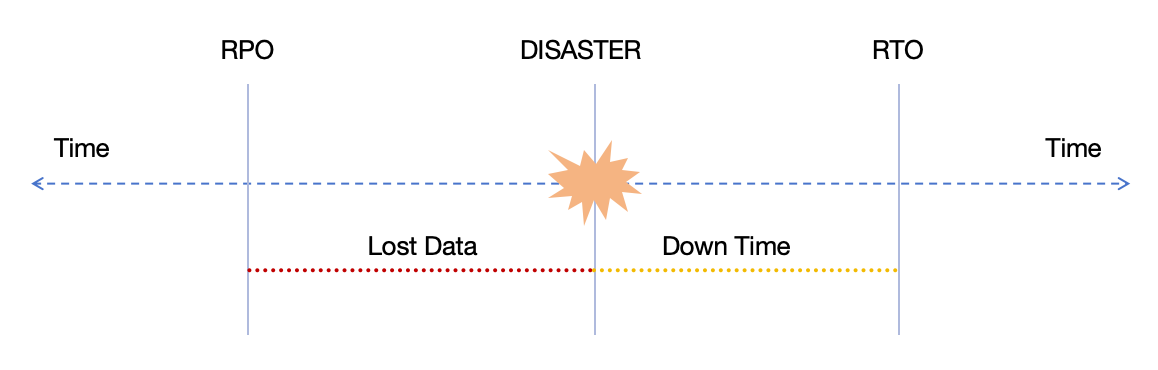
- Recovery Time Objective (RTO): refers to the maximum acceptable amount of time that a business process can be down after a disaster occurs before it negatively impacts the organization.
- Recovery Point Objective (RPO): refers to the maximum acceptable amount of time since the last data recovery point. This determines what is considered an acceptable loss of data between the last recovery point and the interruption of service.
The following figure illustrates these two concepts:
- Write-Ahead Logging (WAL): persistently records every data modification to ensure data integrity and consistency.
GreptimeDB storage engine is a typical LSM Tree :
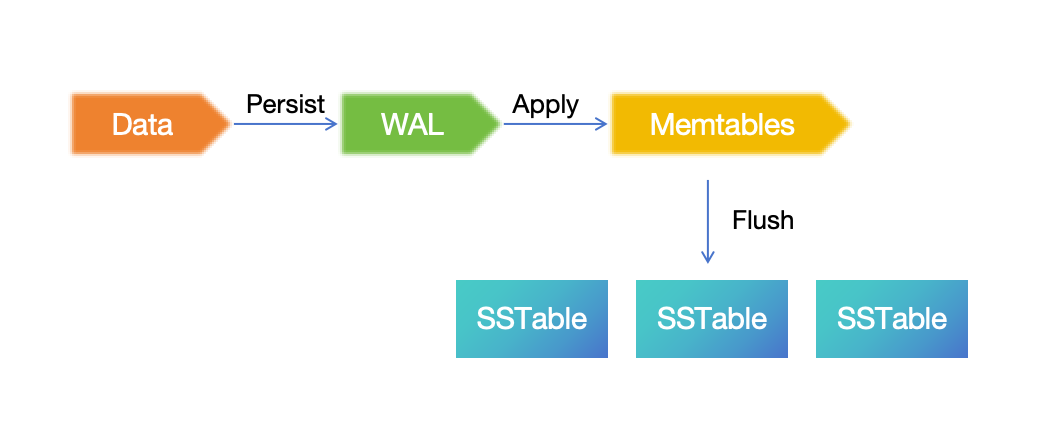
The data written is going firstly persisted into WAL, then applied into Memtable in memory. Under specific conditions (e.g., exceeding the memory threshold), the Memtable will be flushed and persisted as an SSTable. So the DR of WAL and SSTable is key to the DR of GreptimeDB.
- Region: a contiguous segment of a table, and also could be regarded as a partition in some relational databases. Read Table Sharding for more details.
Component architecture
GreptimeDB
Before digging into the specific DR solution, let's explain the architecture of GreptimeDB components in the perspective of DR:
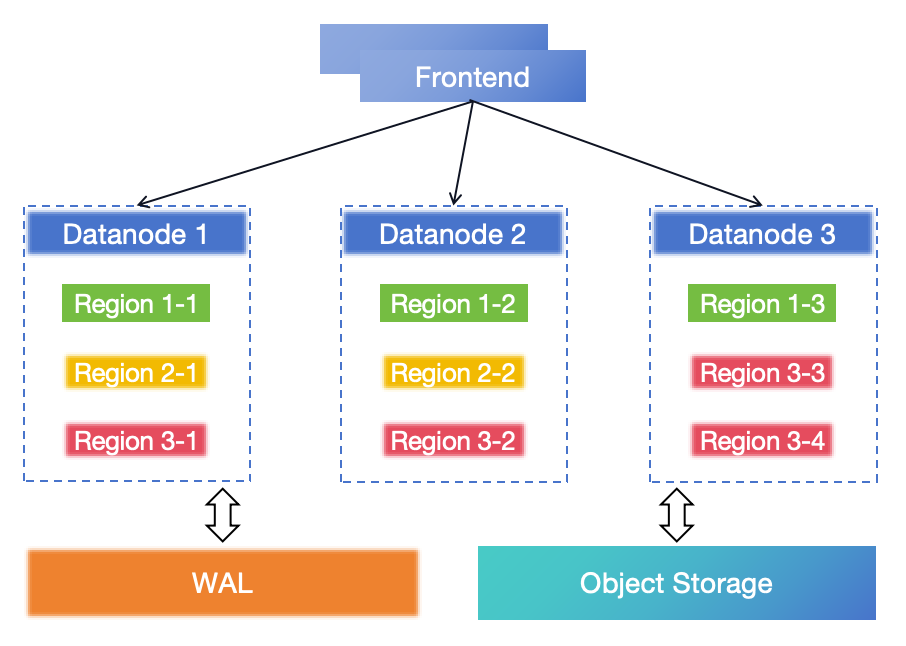
GreptimeDB is designed with a cloud-native architecture based on storage-compute separation:
- Frontend: the ingestion and query service layer, which forwards requests to Datanode and processes, and merges responses from Datanode.
- Datanode: the storage layer of GreptimeDB, and is an LSM storage engine. Region is the basic unit for storing and scheduling data in Datanode. A region is a table partition, a collection of data rows. The data in region is saved into Object Storage (such as AWS S3). Unflushed Memtable data is written into WAL and can be recovered in DR.
- WAL: persists the unflushed Memtable data in memory. It will be truncated when the Memtable is flushed into SSTable files. It can be local disk-based (local WAL) or Kafka cluster-based (remote WAL).
- Object Storage: persists the SSTable data and index.
The GreptimeDB stores data in object storage such as AWS S3 or its compatible services, which is designed to provide 99.999999999% durability and 99.99% availability of objects over a given year. And services such as S3 provide replications in Single-Region or Cross-Region, which is naturally capable of DR.
At the same time, the WAL component is pluggable, e.g. using Kafka as the WAL service that offers a mature DR solution.
Backup and restore
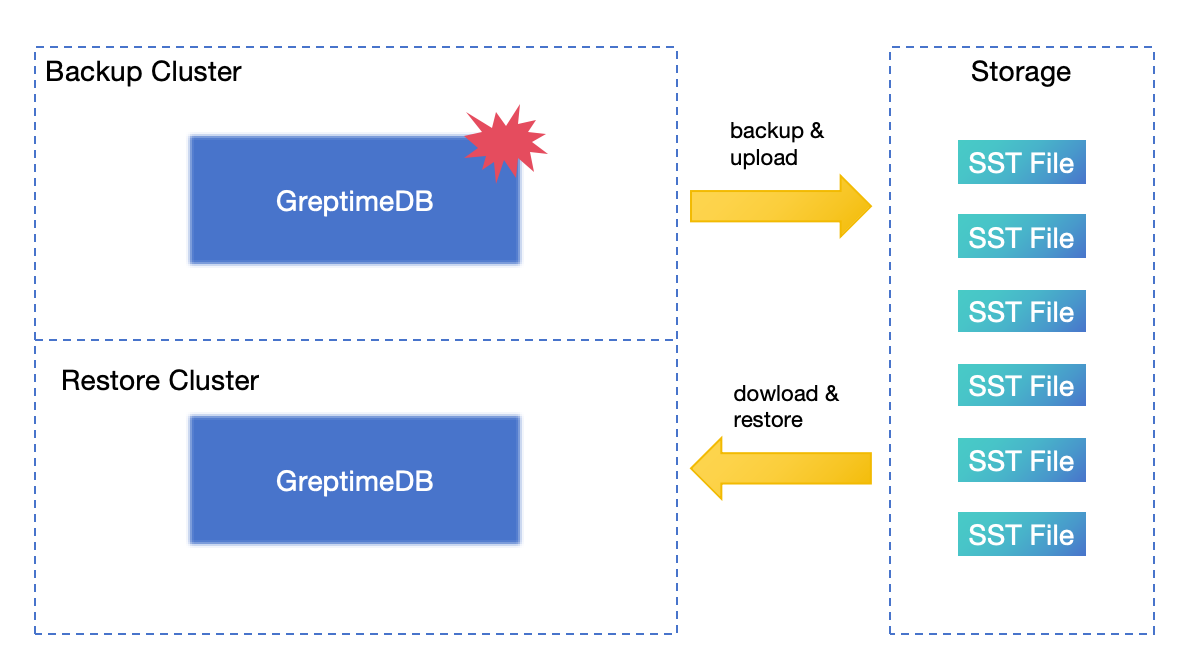
The Backup & Restore (BR) tool can perform a full snapshot backup of databases or tables at a specific time and supports incremental backup. When a cluster encounters a disaster, you can restore the cluster from backup data. Generally speaking, BR is the last resort for disaster recovery.
Solutions introduction
DR solution for GreptimeDB Standalone
If the Standalone is running on the local disk for WAL and data, then:
- RPO: depends on backup frequency.
- RTO: doesn't make sense in standalone mode, mostly depends on the size of the data to be restored, your failure response time, and the operational infrastructure.
A good start is to deploy GreptimeDB Standalone into an IaaS platform that has a backup and recovery solution. For example, Amazon EC2 with EBS volumes provides a comprehensive Backup and Recovery solution.
But if running the Standalone with remote WAL and object storage, there is a better DR solution:
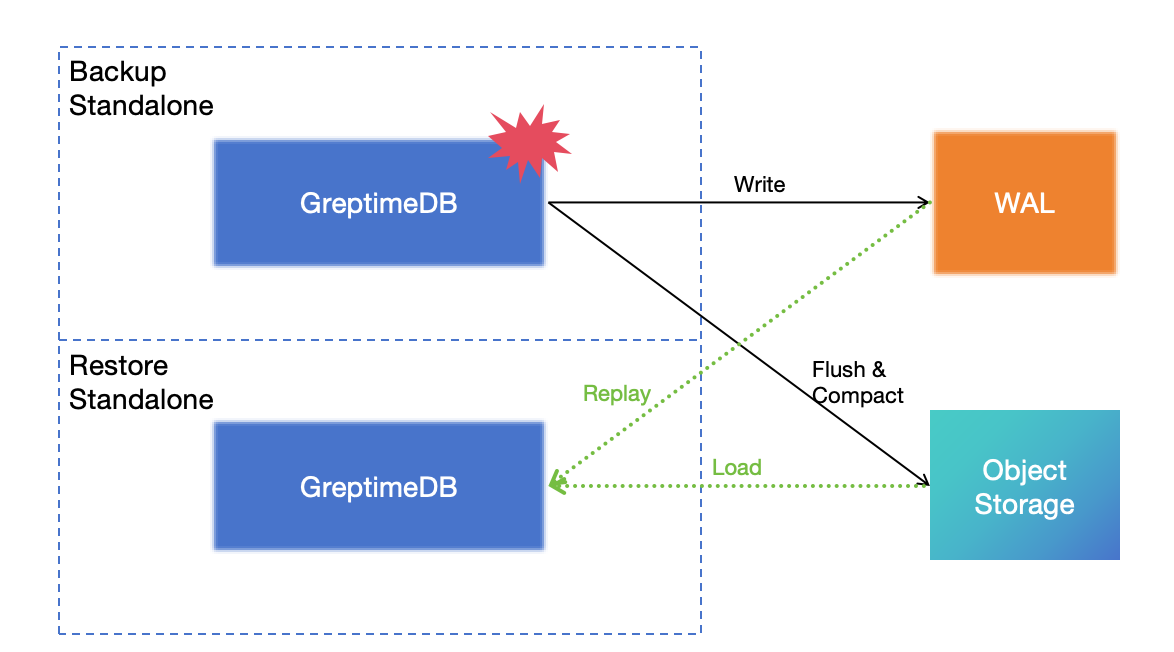
Write the WAL to the Kafka cluster and store the data in object storage, so the database itself is stateless. In the event of a disaster affecting the standalone database, you can restore it using the remote WAL and object storage. This solution can achieve RPO=0 and RTO in minutes.
For more information about this solution, see DR solution for Standalone.
DR solution based on Active-Active Failover
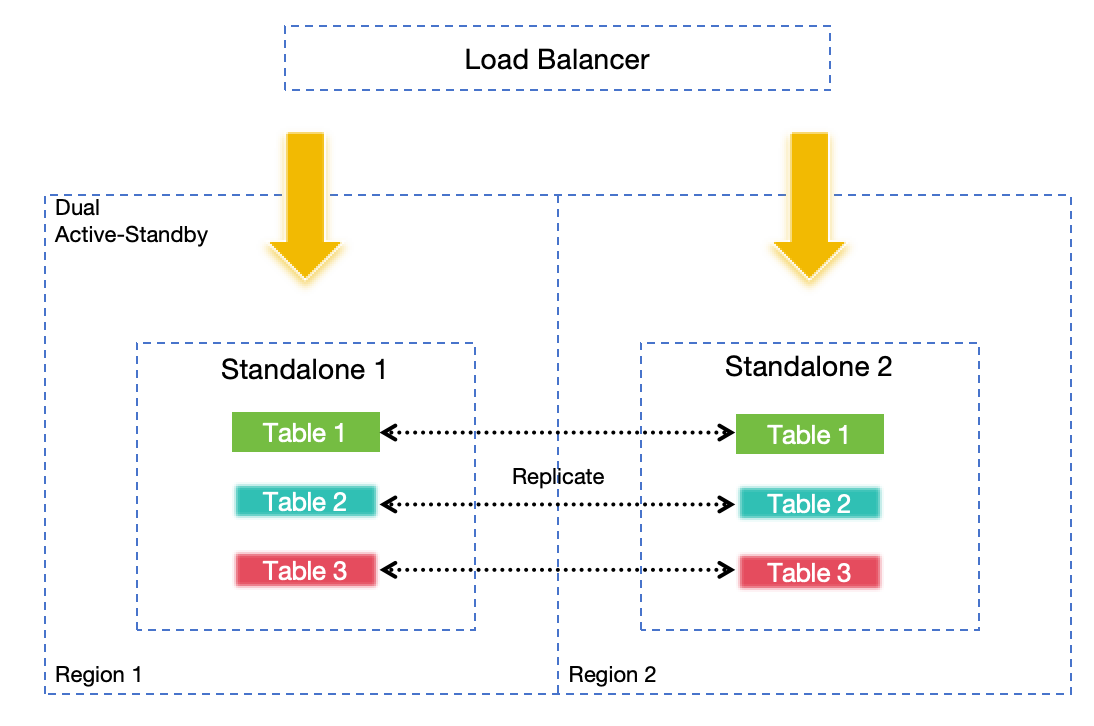
In some edge or small-to-medium scale scenarios, or if you lack the resources to deploy remote WAL or object storage, Active-Active Failover offers a better solution compared to Standalone DR. By replicating requests synchronously between two actively serving standalone nodes, high availability is ensured. The failure of any single node will not lead to data loss or a decrease in service availability even when using local disk-based WAL and data storage.
Deploying nodes in different regions can also meet region-level DR requirements, but the scalability is limited.
Active-Active Failover is only available in GreptimeDB Enterprise.
For more information about this solution, see DR solution based on Active-Active Failover.
DR solution based on cross-region deployment in a single cluster
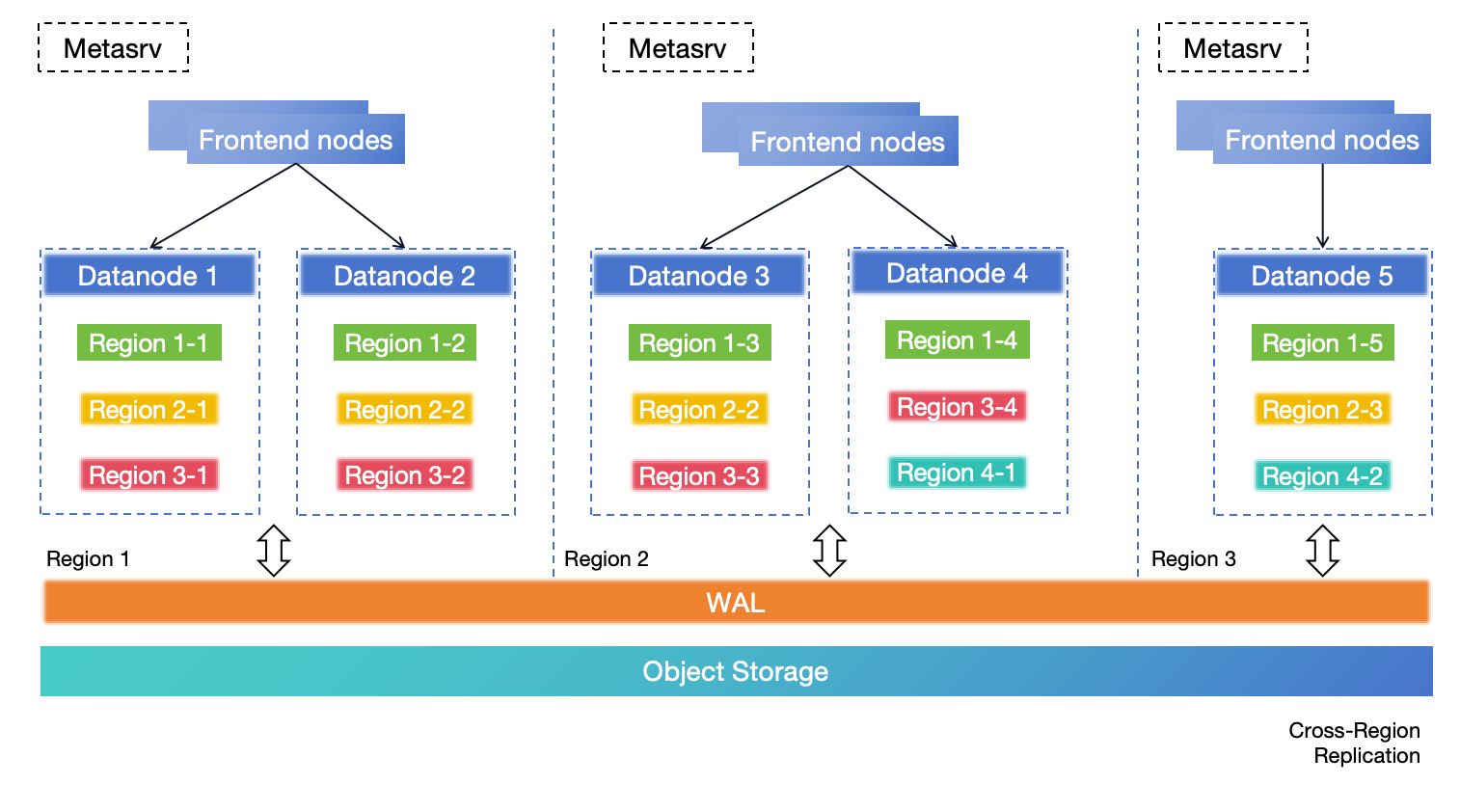
For medium-to-large scale scenarios requiring zero RPO, this solution is highly recommended. In this deployment architecture, the entire cluster spans across three regions, with each region capable of handling both read and write requests. Data replication is achieved using remote WAL and object storage, both of which must have cross-region DR enabled. If Region 1 becomes completely unavailable due to a disaster, the table regions within it will be opened and recovered in the other regions. In the event that Region 1 becomes completely unavailable due to a disaster, the table regions within it will be opened and recovered in the other regions. Region 3 serves as a replica to adhere to the majority protocol of Metasrv.
This solution provides region-level error tolerance, scalable write capability, zero RPO, and minute-level RTO or even lower. For more information about this solution, see DR solution based on cross-region deployment in a single cluster.
DR solution based on BR
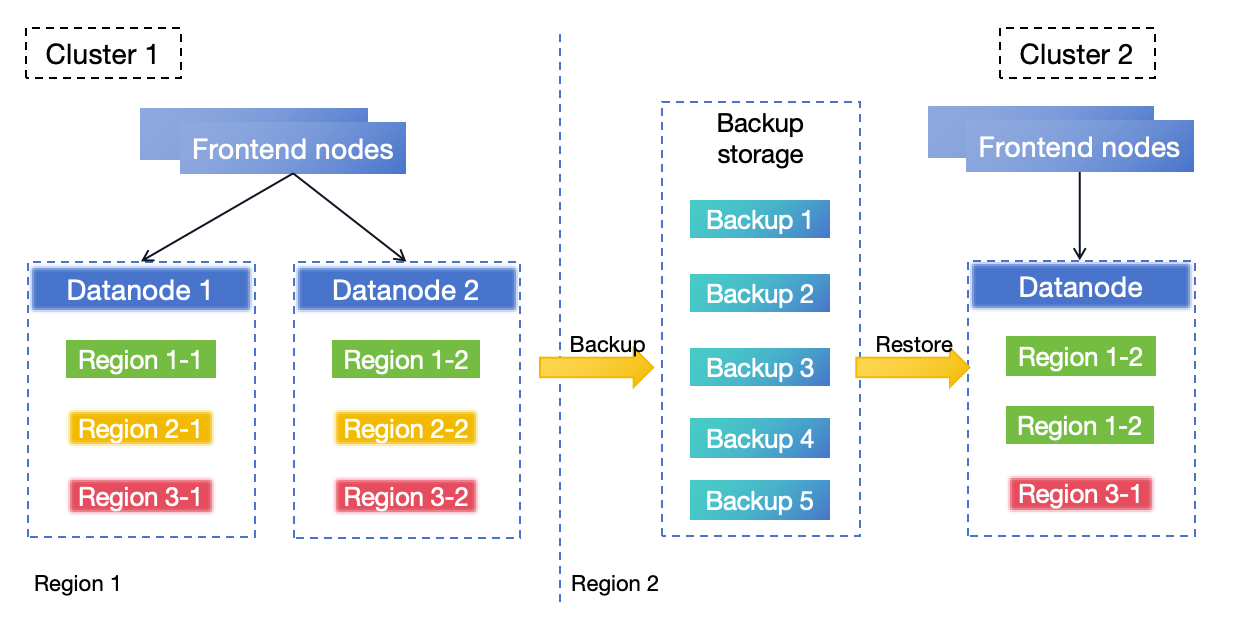
In this architecture, GreptimeDB Cluster 1 is deployed in region 1. The BR process continuously and regularly backs up the data from Cluster 1 to region 2. If region 1 experiences a disaster rendering Cluster 1 unrecoverable, you can use the backup data to restore a new cluster (Cluster 2) in region 2 to resume services.
The DR solution based on BR provides an RPO depending on the backup frequency and an RTO that varies with the size of the data to be restored.
Read Backup & restore data for details, and we plan to provide a BR tool in-house for this solution.
Solution Comparison
By comparing these DR solutions, you can decide on the final option based on their specific scenarios, requirements, and cost.
| DR solution | Error Tolerance Objective | RPO | RTO | TCO | Scenarios | Remote WAL & Object Storage | Notes |
|---|---|---|---|---|---|---|---|
| DR solution for Standalone | Single-Region | Backup Interval | Minute or Hour level | Low | Low requirements for availability and reliability in small scenarios | Optional | |
| DR solution based on Active-Active Failover | Cross-Region | 0 | Minute level | Low | High requirements for availability and reliability in small-to-medium scenarios | Optional | Commercial feature |
| DR solution based on cross-region deployment in a single cluster | Multi-Regions | 0 | Minute level | High | High requirements for availability and reliability in medium-to-large scenarios | Required | |
| DR solution based on BR | Single-Region | Backup Interval | Minute or Hour level | Low | Acceptable requirements for availability and reliability | Optional |