Distributed Querying
We know how data is distributed in GreptimeDB (see "Table Sharding") , then how to query it? Distributed querying is very simple in GreptimeDB. In short, we just split the query into sub-queries, each of which is responsible for querying an individual part of the table's data. Then we merge all results into a final result. A typical "Split-Merge" methodology here. In detail, let's start from the time when a query arrives at Frontend.
When a query arrives at Frontend, it's first been parsed into a SQL abstract syntax tree(AST). We traverse the ast, and generate a logical plan from it. As the name suggests, a logical plan is just a "hint" of how to execute the query "logically". It can't be run directly, so we further generate an executable physical plan from it. The physical plan is a tree-like data structure, each node actually indicates the executing method of the query. Once we run the physical plan tree from top to bottom, the resulting data will flow from leaf to root, being merged or calculated. Finally we got the query's result at the root's output.
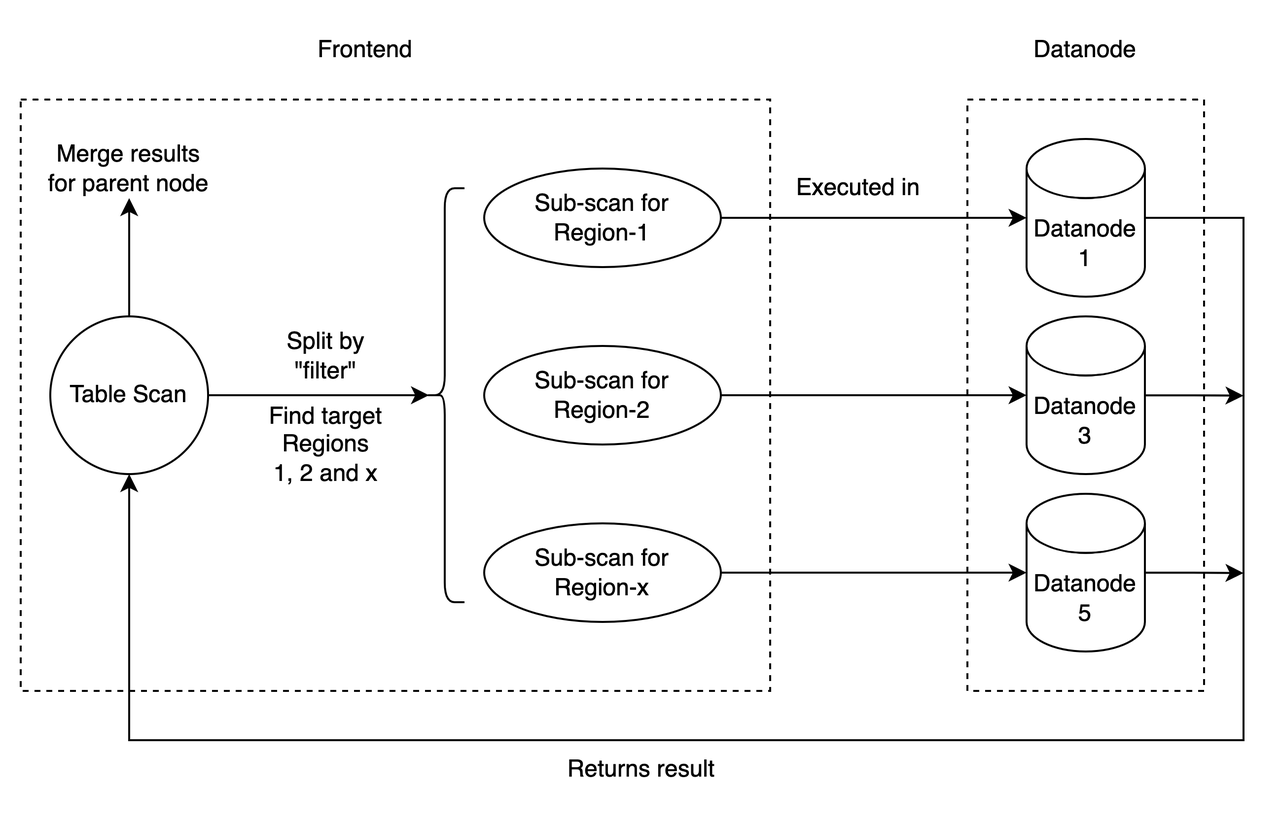
Until now, it's just a typical "volcano" query execution model you can find in almost every SQL database. So where does the "distribute" happen? It's all happened in a physical plan node called "TableScan". A "TableScan" is a leaf node in a physical plan tree, it is responsible for scanning a table's data (as its name suggests obviously). When Frontend is about to execute a table scan, it first needs to split the table scan into smaller scans, by each region's data range.
All regions of a table have ranges of their stored data. Take the following table for example:
CREATE TABLE my_table (
a INT,
others STRING,
)
PARTITION BY RANGE (a) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20),
PARTITION p2 VALUES LESS THAN MAXVALUE,
)CREATE TABLE my_table (
a INT,
others STRING,
)
PARTITION BY RANGE (a) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20),
PARTITION p2 VALUES LESS THAN MAXVALUE,
)my_table is created with 3 partitions. In current implementation of GreptimeDB, 3 regions will be created for the table(partitions to regions is 1:1). Then the 3 regions will have the ranges of "[-∞, 10)", "[10, 20)" and "[20, +∞)" respectively. If provided with a value, for example, "42", we search through the ranges, and find the corresponding region that contains the value (region 3 in this case).
As to a query, we use the "filter" to find the regions. "Filter" is the condition in "WHERE" clause. For example, a query of SELECT * FROM my_table WHERE a < 10 AND b > 10, its "filter" is "a < 10 AND b > 10". We then check the ranges, finding out all regions that contain values that satisfy the filter.
If the query does not have any filters, it's treated as a full-region scan.
After the desired regions are found, we just assemble sub-scan in it. In this way, we split a query into sub-queries, each of which would retrieve some part of the table's data. The sub-query is executed in Datanode, and is waiting to be finished in Frontend. Their results are merged as the final output of the table scan node.
The following picture summarized the above procedure of the distributed query execution: