Data Persistence and Indexing
Similar to all LSMT-like storage engines, data in MemTables is persisted to durable storage, for example, the local disk file system or object storage service. GreptimeDB adopts Apache Parquet as its persistent file format.
SST File Format
Parquet is an open source columnar format that provides fast data querying and has already been adopted by many projects, such as Delta Lake.
Parquet has a hierarchical structure like "row groups-columns-data pages". Data in a Parquet file is horizontally partitioned into row groups, in which all values of the same column are stored together to form a data page. Data page is the minimal storage unit. This structure greatly improves performance.
First, clustering data by column makes file scanning more efficient, especially when only a few columns are queried, which is very common in analytical systems.
Second, data of the same column tends to be homogeneous which helps with compression when apply techniques like dictionary and Run-Length Encoding (RLE).
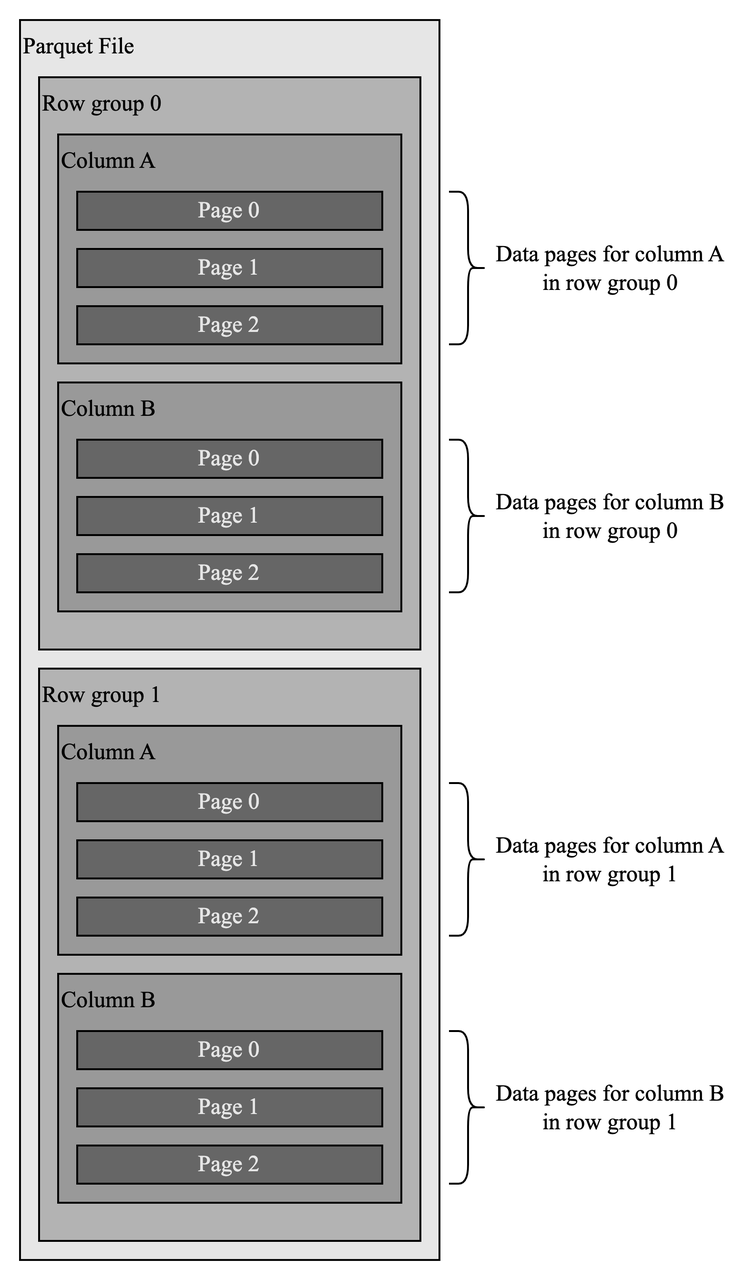
Data Persistence
GreptimeDB provides a configuration item storage.flush.global_write_buffer_size, which is flush threshold of the total memory usage for all MemTables.
When the size of data buffered in MemTables reaches that threshold, GreptimeDB will pick MemTables and flush them to SST files.
Indexing Data in SST Files
Apache Parquet file format provides inherent statistics in headers of column chunks and data pages, which are used for pruning and skipping.
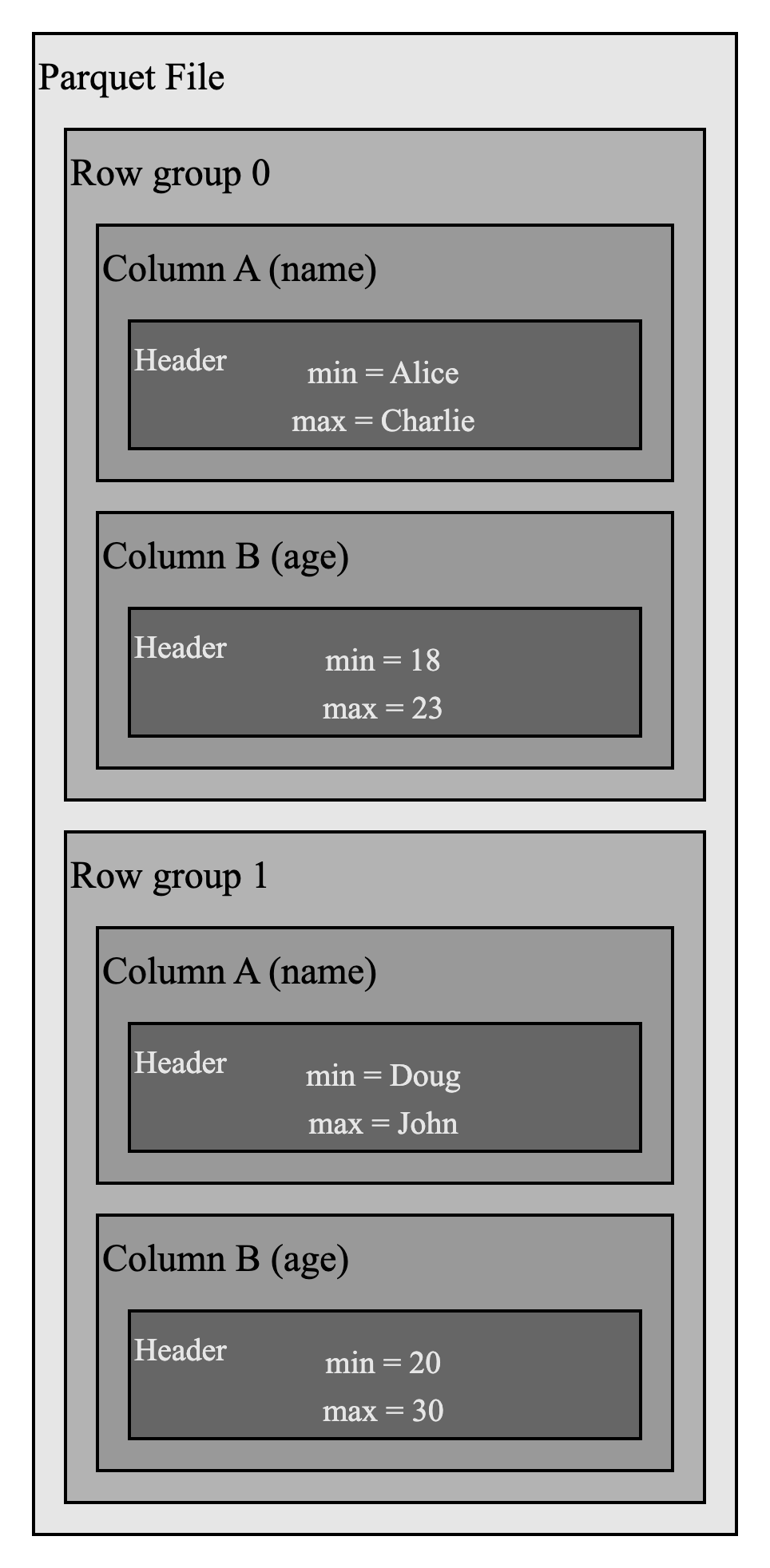
For example, in the above Parquet file, if you want to filter rows where name = Emily, you can easily skip row group 0 because the max value for name field is Charlie. This statistical information reduces IO operations.
Besides Parquet's built-in statistics, our team is working on supporting a separate index file that utilizes some time-series specific indexing techniques to improve scanning performance.
Unified Data Access Layer: OpenDAL
GreptimeDB uses OpenDAL to provide a unified data access layer, thus, the storage engine does not need to interact with different storage APIs, and data can be migrated to cloud-based storage like AWS S3 seamlessly.