问题排查
在遇到错误或者性能问题时,我们可以基于指标和日志了解 GreptimeDB 的状态。这些信息也可以帮助进一步排查问题的原因。 以下列举了部分常见异常情况的排查方法。对于无法简单定位原因的情况,提供指标和日志给官方团队也能提高官方排查问题的效率。
查看 CPU 和 Memory 负载
可直接从 Dashboard 中查看对应组件的 CPU 和 Memory 负载,其中 CPU 显示的是 millicore,Memory 则是当前进程的 RSS。此时需要要关注对应的 CPU 和 Memory 负载是否有超过 Pod 的 Limit,如果 CPU 已经触碰到 Pod 的 Limit,那么将会触发 throttle,用户可感受的现象就是请求处理变慢;如果 Memory 已经到达 Limit 超过 70%,那么将有可能会被 OOM。
创建 flow 失败
创建 flow 失败时,一个场景的原因是没有部署 flownode,可以检查
- 集群中是否部署了 flownode
- 集群中 flownode 状态是否 READY
如果已经部署了 flownode,则可以通过排查 metasrv 和 flownode 的日志进一步排查,也可以通过内部表查看 flow 节点是否成功创建:
select * from information_schema.cluster_info;
对象存储配置问题
对象存储配置不对时,GreptimeDB 访问对象存储会出现异常。如果 GreptimeDB 没有存储任何数据,一般不需要访问对象存储,因此刚部署完成时可能观察不到错误。当创建一张表或者开始通过写入协议往 GreptimeDB 写入数据后,则可以观察到请求报错。
通常 DB 返回错误信息会包含对象存储的报错。可以通过 DB 的错误日志找到对象存储具体的报错信息。一些常见的错误原因包括
- Access Key 或 Secret Access Key 填写错误
- 对象存储的权限配置不对
- 如果使用的是腾讯云 COS 的 S3 兼容 API,由于腾讯云禁用了 path-style 域名,需要在 GreptimeDB 的 S3 配置中设置
enable_virtual_host_style = true
以 S3 为例,GreptimeDB 需要用到的权限包括
"s3:PutObject",
"s3:ListBucket",
"s3:GetObject",
"s3:DeleteObject"
写入吞吐低
通过大盘里的 Ingestion 相关面板可以观察到写入的吞吐:
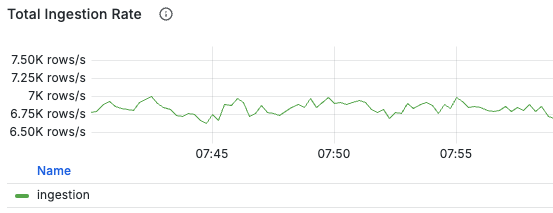
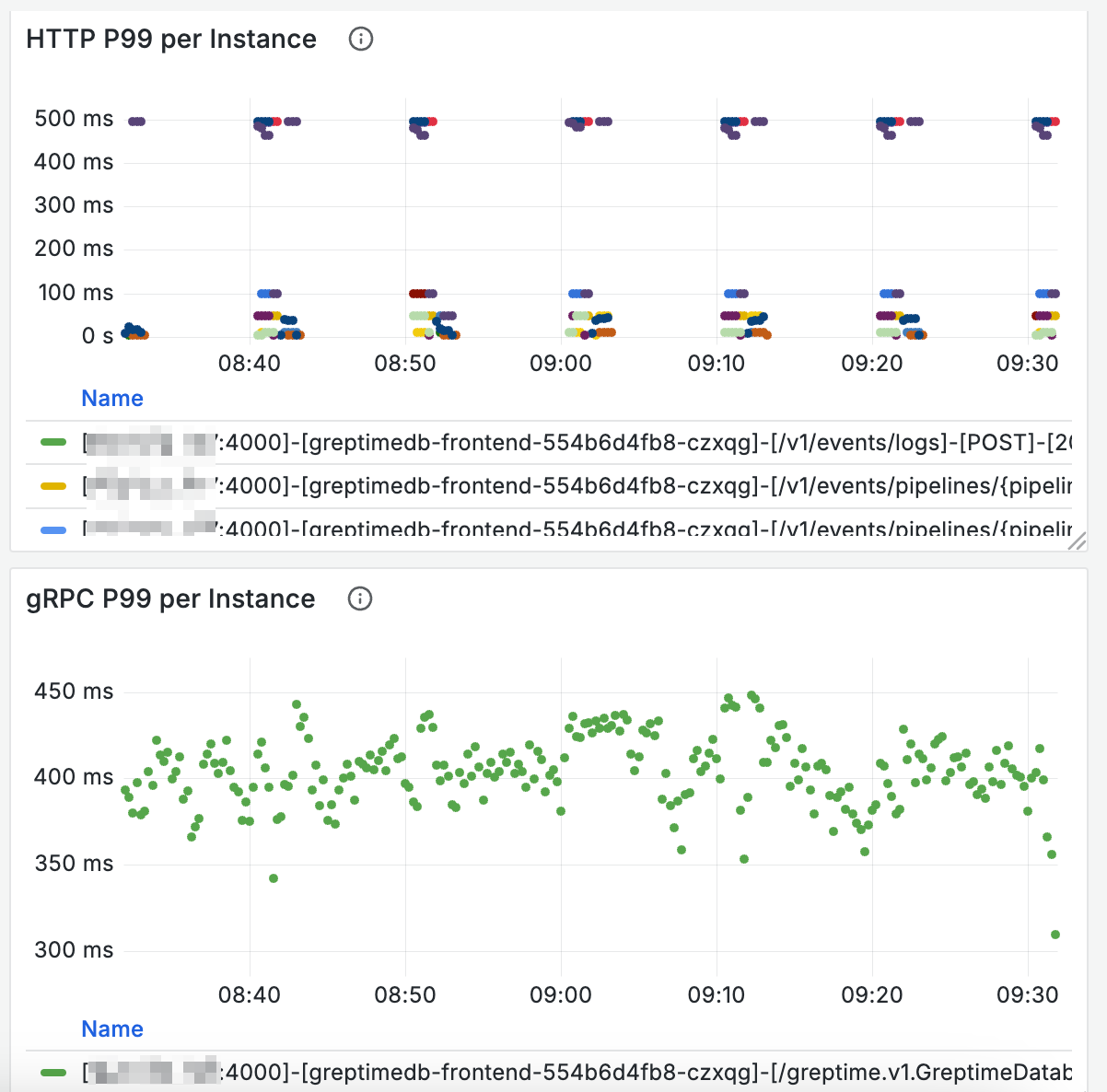
如果写入吞吐低于预期压力,那么有可能是写入延时较高,DB 出现积压导致的。大盘在 Frontend Requests 区域中提供了一些面板来观察请求的耗时:
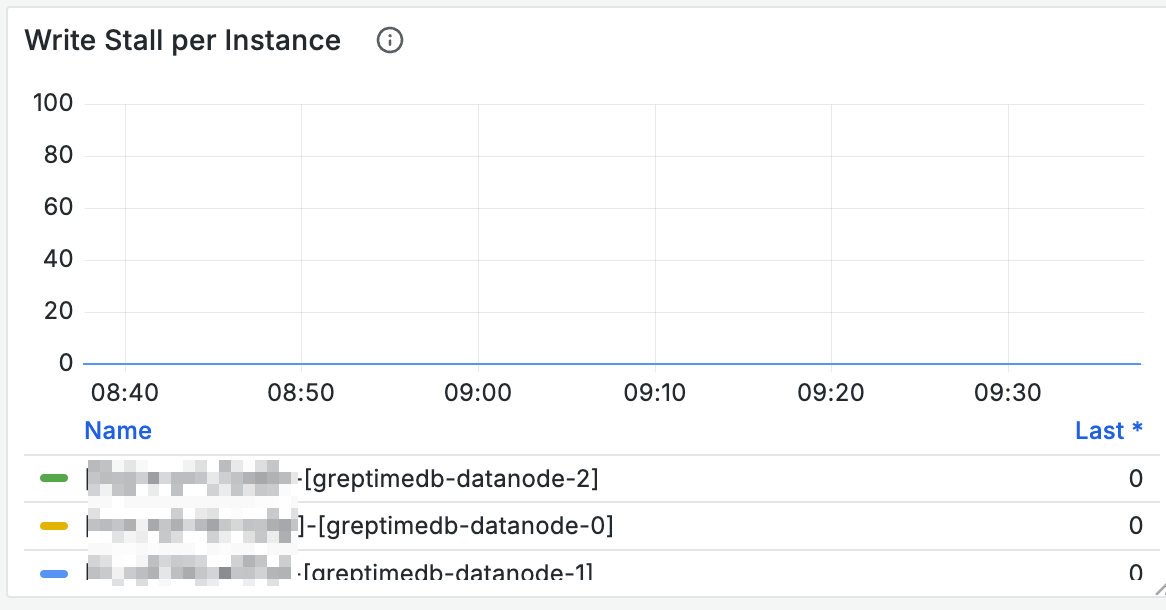
你可以通过 Mito Engine 区域的 Write Stall 面板观察是否有节点出现了 stall(stall 的值长时间超过 0)。
如果有,则说明节点写入出现了瓶颈。
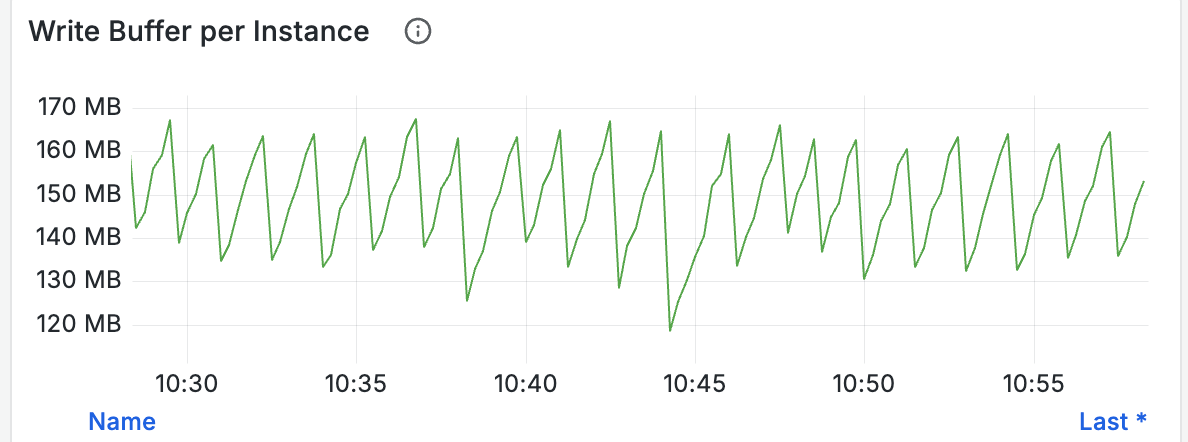
通过观察 Write Buffer 的面板也可以观察用于写入的 buffer 的大小变化,如果 buffer 很快被写满,那么可以考虑成比例调大 global_write_buffer_size 和 global_write_buffer_reject_size:
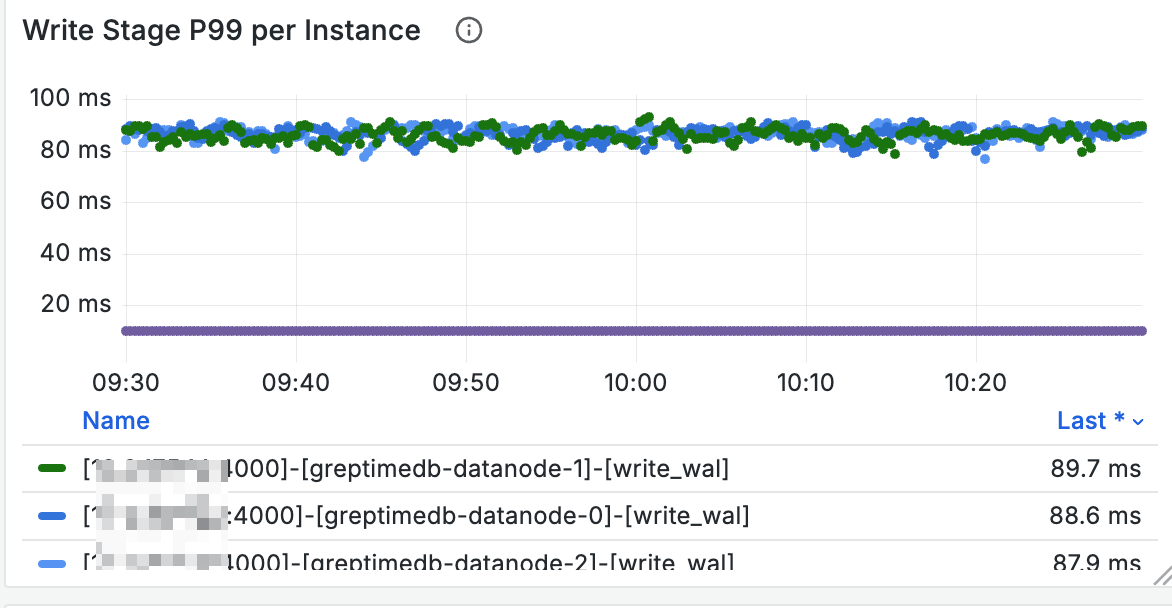
通过 Write Stage 面板可以查看写入耗时高的阶段:
可以通过 Compaction/Flush 相关面板查看后台任务的情况
- 是否出现频繁的 flush 操作,如果有,则可以考虑成比例调大
global_write_buffer_size和global_write_buffer_reject_size - 是否有长时间的 compaction 和 flush 操作,如果有,则写入有可能受这些后台任务影响
此外,通过日志里 flush memtables 相关的日志可以看到单次 flush 的耗时,
写入内存消耗过高
DB 写入过程中会估算出当前所有 memtable 的总大小。可以通过 Write Buffer 面板查看 memtable 的内存占用。
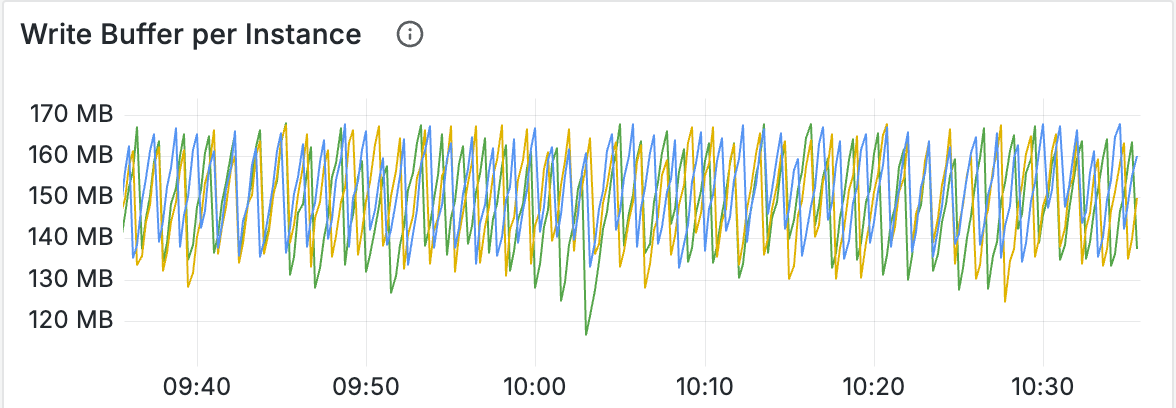
注意这部分的值可能比实际申请的内存要小。
如果发现写入时 DB 的内存增长速度过快,或者写入经常出现 OOM 的情况,则可能跟表结构设计不合理有关。
一个常见的原因是主键(Primary Key)设计不合理。如果主键的数量过多,则会导致写入时消耗非常多的内存,可能导致数据库内存占用过大。出现这种情况时,往往 Write Buffer 会长期处于高位置。这种情况增加写入 buffer 的大小一般不会改善问题,需要减少主键的列数,或者去掉高基数的主键列。
查询耗时高
如果查询的耗时较高,可以通过在查询前面加上 EXPLAIN ANALYZE 或 EXPLAIN ANALYZE VERBOSE 重新执行。查询的结果会带上各个阶段执行的耗时用于协助排查。
此外 Read Stage 的面板也能协助了解不同阶段的查询耗时:
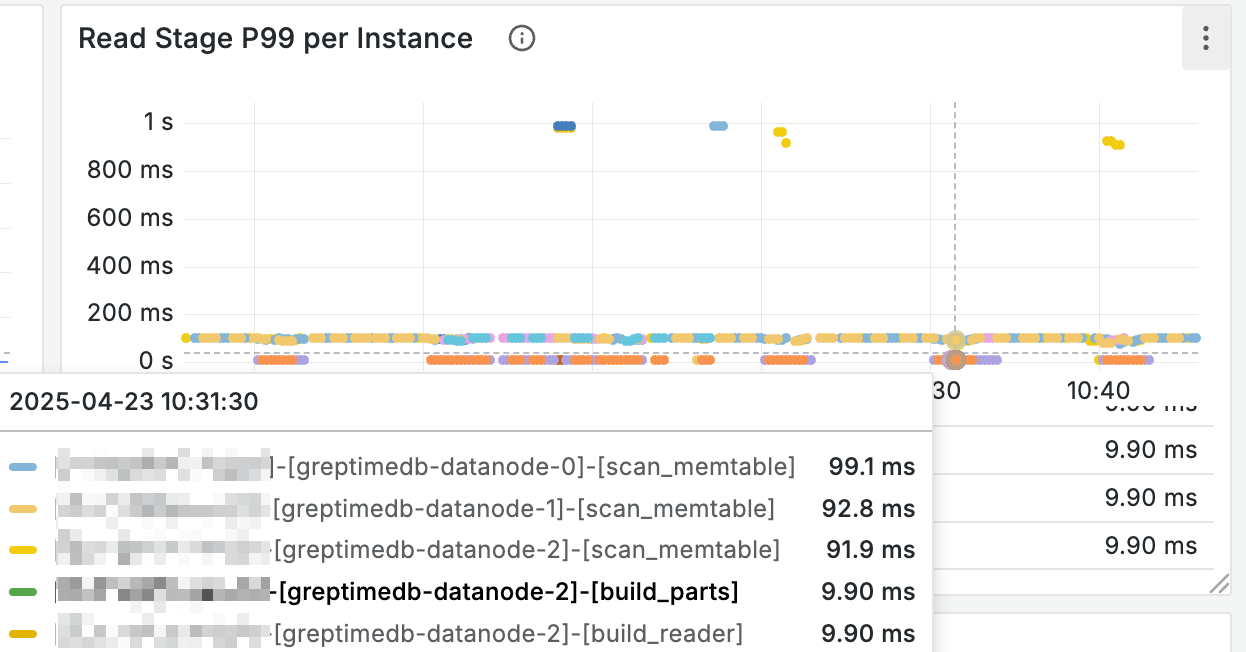
缓存写满
如果需要了解各个缓存的大小,可以通过 Cached Bytes 面板查询节不同缓存已经使用的大小:
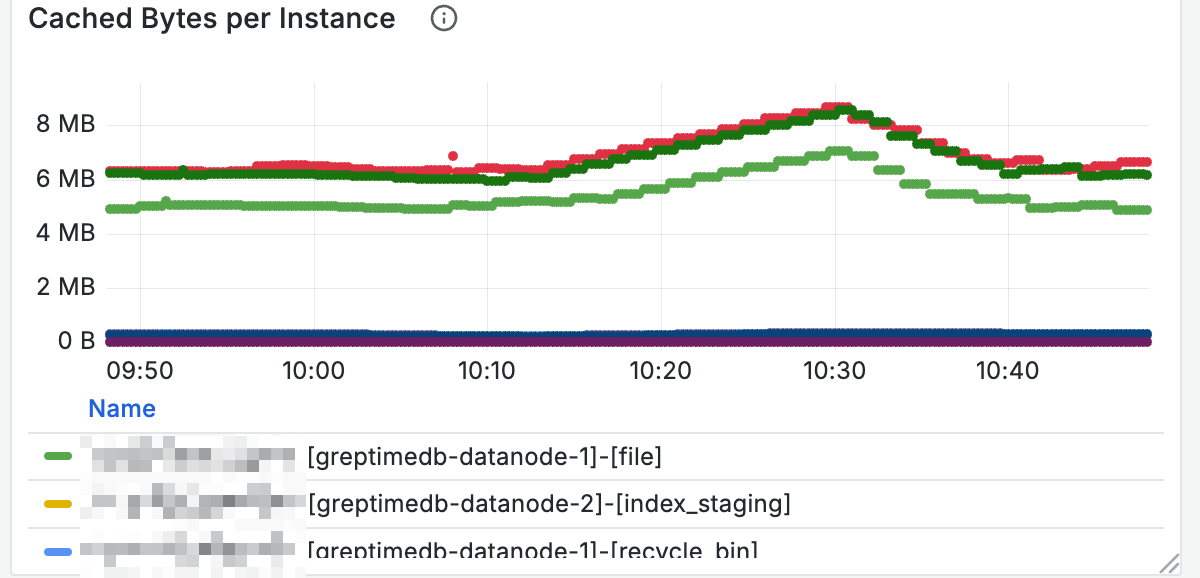
对于查询耗时高的节点,也可以通过查询缓存大小来判断是否缓存已经写满。
对象存储耗时
可以通过大盘中的 OpenDAL 区域的面板查看对象存储操作的耗时,例如以下面板是对象存储写入操作的响应耗时:
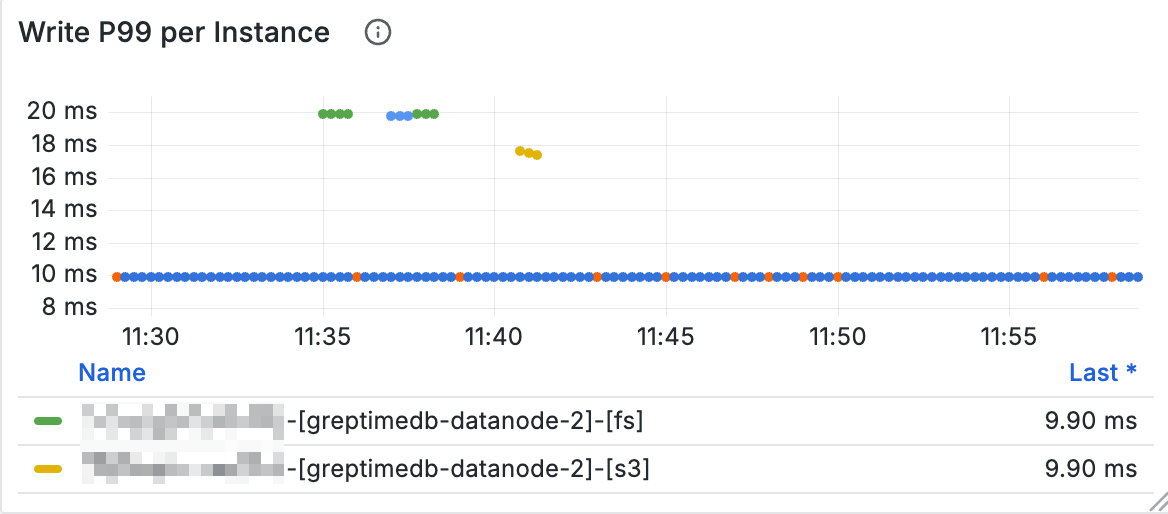
如果怀疑对象存储操作出现抖动,可以观察相关的面板。