管理 ETCD
GreptimeDB 集群默认需要一个 etcd 集群用于元数据存储。让我们使用 Bitnami 的 etcd Helm chart 安装一个 etcd 集群。
先决条件
- Kubernetes >= v1.23
- kubectl >= v1.18.0
- Helm >= v3.0.0
安装
将以下配置保存为文件 etcd.yaml:
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.5.21-debian-12-r5
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
安装 etcd 集群:
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 11.3.4 \
-n etcd-cluster \
--values etcd.yaml
等待 etcd 集群运行:
kubectl get pod -n etcd-cluster
Expected Output
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 64s
etcd-1 1/1 Running 0 65s
etcd-2 1/1 Running 0 72s
等待 etcd 集群运行完毕,使用以下命令检查 etcd 集群的健康状态:
kubectl -n etcd-cluster \
exec etcd-0 -- etcdctl \
--endpoints etcd-0.etcd-headless.etcd-cluster:2379,etcd-1.etcd-headless.etcd-cluster:2379,etcd-2.etcd-headless.etcd-cluster:2379 \
endpoint status -w table
Expected Output
+----------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| etcd-0.etcd-headless.etcd-cluster:2379 | 680910587385ae31 | 3.5.15 | 20 kB | false | false | 4 | 73991 | 73991 | |
| etcd-1.etcd-headless.etcd-cluster:2379 | d6980d56f5e3d817 | 3.5.15 | 20 kB | false | false | 4 | 73991 | 73991 | |
| etcd-2.etcd-headless.etcd-cluster:2379 | 12664fc67659db0a | 3.5.15 | 20 kB | true | false | 4 | 73991 | 73991 | |
+----------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
备份
在 bitnami etcd chart 中,使用共享存储卷 Network File System (NFS) 存储 etcd 备份数据。通过 Kubernetes 中的 CronJob 进行 etcd 快照备份,并挂载 NFS PersistentVolumeClaim (PVC),可以将快照传输到 NFS 中。
添加以下配置,并将其命名为 etcd-backup.yaml 文件,注意需要将 existingClaim 修改为你的 NFS PVC 名称:
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.5.21-debian-12-r5
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Backup settings
disasterRecovery:
enabled: true
cronjob:
schedule: "*/30 * * * *"
historyLimit: 2
snapshotHistoryLimit: 2
pvc:
existingClaim: "${YOUR_NFS_PVC_NAME_HERE}"
重新部署 etcd 集群:
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 11.3.4 \
-n etcd-cluster \
--values etcd-backup.yaml
你可以看到 etcd 备份计划任务:
kubectl get cronjob -n etcd-cluster
Expected Output
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
etcd-snapshotter */30 * * * * <none> False 0 <none> 36s
kubectl get pod -n etcd-cluster
Expected Output
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 35m
etcd-1 1/1 Running 0 36m
etcd-2 0/1 Running 0 6m28s
etcd-snapshotter-28936038-tsck8 0/1 Completed 0 4m49s
kubectl logs etcd-snapshotter-28936038-tsck8 -n etcd-cluster
Expected Output
etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 2.698457ms
etcd 11:18:07.47 INFO ==> Snapshotting the keyspace
{"level":"info","ts":"2025-01-06T11:18:07.579095Z","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/snapshots/db-2025-01-06_11-18.part"}
{"level":"info","ts":"2025-01-06T11:18:07.580335Z","logger":"client","caller":"[email protected]/maintenance.go:212","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":"2025-01-06T11:18:07.580359Z","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379"}
{"level":"info","ts":"2025-01-06T11:18:07.582124Z","logger":"client","caller":"[email protected]/maintenance.go:220","msg":"completed snapshot read; closing"}
{"level":"info","ts":"2025-01-06T11:18:07.582688Z","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379","size":"20 kB","took":"now"}
{"level":"info","ts":"2025-01-06T11:18:07.583008Z","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/snapshots/db-2025-01-06_11-18"}
Snapshot saved at /snapshots/db-2025-01-06_11-18
接下来,可以在 NFS 服务器中看到 etcd 备份快照:
ls ${NFS_SERVER_DIRECTORY}
Expected Output
db-2025-01-06_11-18 db-2025-01-06_11-20 db-2025-01-06_11-22
恢复
当您遇到 etcd 数据丢失或损坏(例如,存储在 etcd 中的关键信息被意外删除,或者发生无法恢复的灾难性集群故障)时,您需要执行 etcd 恢复。此外,恢复 etcd 还可用于开发和测试目的。
恢复前需要停止向 etcd 集群写入数据(停止 GreptimeDB Metasrv 对 etcd 的写入),并创建最新的快照文件用于恢复。
添加以下配置文件,命名为 etcd-restore.yaml。注意,existingClaim 是你的 NFS PVC 的名字,snapshotFilename 为 etcd 快照文件名:
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.5.21-debian-12-r5
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Restore settings
startFromSnapshot:
enabled: true
existingClaim: "${YOUR_NFS_PVC_NAME_HERE}"
snapshotFilename: "${YOUR_ETCD_SNAPSHOT_FILE_NAME}"
部署 etcd 恢复集群:
helm upgrade \
--install etcd-recover oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 11.3.4 \
-n etcd-cluster \
--values etcd-restore.yaml
等待 etcd 恢复集群运行:
kubectl get pod -n etcd-cluster -l app.kubernetes.io/instance=etcd-recover
Expected Output
NAME READY STATUS RESTARTS AGE
etcd-recover-0 1/1 Running 0 91s
etcd-recover-1 1/1 Running 0 91s
etcd-recover-2 1/1 Running 0 91s
接着,将 Metasrv 的 etcdEndpoints 改成新的 etcd recover 集群,本例中为 "etcd-recover.etcd-cluster.svc.cluster.local:2379":
apiVersion: greptime.io/v1alpha1
kind: GreptimeDBCluster
metadata:
name: greptimedb
spec:
# 其他配置
meta:
etcdEndpoints:
- "etcd-recover.etcd-cluster.svc.cluster.local:2379"
然后重启 GreptimeDB Metasrv 完成 etcd 恢复。
Monitoring
- 安装 Prometheus Operator (例如: kube-prometheus-stack).
- 安装 podmonitor CRD.
将以下配置保存为文件 etcd-monitoring.yaml:
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.5.21-debian-12-r5
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Monitoring settings
metrics:
enabled: true
podMonitor:
enabled: true
namespace: etcd-cluster
interval: 10s
scrapeTimeout: 10s
additionalLabels:
release: prometheus
部署并监控 etcd:
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 11.3.4 \
-n etcd-cluster \
--values etcd-monitoring.yaml
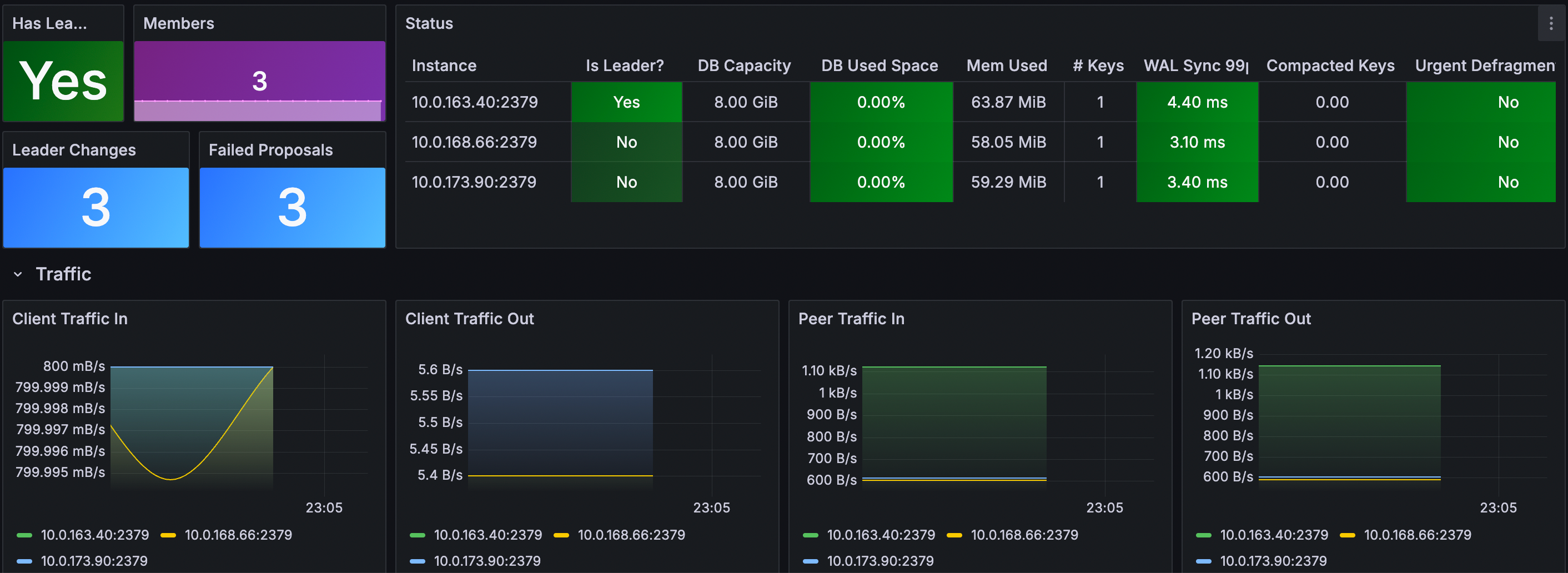
Grafana dashboard
使用 ETCD Cluster Overview dashboard (ID: 15308) 来监控 etcd 的指标.
- 登录你的 Grafana.
- 导航至 Dashboards -> New -> Import.
- 输入 Dashboard ID: 15308, 选择数据源并加载图表.
⚠️ Defrag - Critical Warning
Defrag 是一项高风险操作,可能会严重影响您的 ETCD 集群及其依赖系统(例如 GreptimeDB):
- 执行期间会阻止所有读/写操作(集群将不可用)。
- 高 I/O 使用率可能导致客户端应用程序超时。
- 如果碎片整理耗时过长,可能会触发领导者选举。
- 如果资源分配不当,可能会导致 OOM 终止。
- 如果在过程中中断,可能会损坏数据。
ETCD 使用多版本并发控制 (MVCC) 机制,用于存储多个版本的 KV。随着时间的推移,随着数据的更新和删除,后端数据库可能会变得碎片化,从而增加存储空间并降低性能。Defrag 是指压缩这些存储空间以回收空间并提高性能的过程。
在 etcd-defrag.yaml 文件中添加以下与 defrag 相关的配置:
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.5.21-debian-12-r5
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Defragmentation settings
defrag:
enabled: true
cronjob:
schedule: "0 3 * * *" # Daily at 3:00 AM
suspend: false
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
部署 etcd 集群并开启 defrag 功能:
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 11.3.4 \
-n etcd-cluster \
--values etcd-defrag.yaml
你可以看到 etcd defrag 定时任务:
kubectl get cronjob -n etcd-cluster
Expected Output
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
etcd-defrag 0 3 * * * <none> False 0 <none> 34s
kubectl get pod -n etcd-cluster
Expected Output
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 4m30s
etcd-1 1/1 Running 0 4m29s
etcd-2 1/1 Running 0 4m29s
etcd-defrag-29128518-sstbf 0/1 Completed 0 90s
kubectl logs etcd-defrag-29128518-sstbf -n etcd-cluster
Expected Output
Finished defragmenting etcd member[http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379]
Finished defragmenting etcd member[http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379]
Finished defragmenting etcd member[http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379]