部署 GreptimeDB 集群
在该指南中,你将学会如何使用 GreptimeDB Operator 在 Kubernetes 上部署 GreptimeDB 集群。
以下输出可能会因 Helm chart 版本和具体环境的不同而有细微差别。
前置条件
创建一个测试 Kubernetes 集群
不建议在生产环境或性能测试中使用 kind。如有这类需求建议使用公有云托管的 Kubernetes 服务,如 Amazon EKS、Google GKE 或 Azure AKS,或者自行搭建生产级 Kubernetes 集群。
目前有很多方法可以创建一个用于测试的 Kubernetes 集群。在本指南中,我们将使用 kind 来创建一个本地 Kubernetes 集群。如果你想使用已有的 Kubernetes 集群,可以跳过这一步。
这里是一个使用 kind v0.20.0 的示例:
kind create cluster
预期输出
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.27.3) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Thanks for using kind! 😊
使用以下命令检查集群的状态:
kubectl cluster-info
预期输出
Kubernetes control plane is running at https://127.0.0.1:60495
CoreDNS is running at https://127.0.0.1:60495/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
中国大陆用户如有网络访问问题,可使用 Greptime 提供的位于阿里云镜像仓库的 kindest/node:v1.27.3 镜像:
kind create cluster --image greptime-registry.cn-hangzhou.cr.aliyuncs.com/kindest/node:v1.27.3
添加 Greptime Helm 仓库
中国大陆用户如有网络访问问题,可跳过这一步骤并直接参考下一步中使用阿里云 OCI 镜像仓库的方式。采用这一方式将无需手动添加 Helm 仓库。
我们提供了 GreptimeDB Operator 和 GreptimeDB 集群的官方 Helm 仓库。你可以通过运行以下命令来添加仓库:
helm repo add greptime https://greptimeteam.github.io/helm-charts/
helm repo update
检查 Greptime Helm 仓库中的 charts:
helm search repo greptime
预期输出
NAME CHART VERSION APP VERSION DESCRIPTION
greptime/greptimedb-cluster 0.2.25 0.9.5 A Helm chart for deploying GreptimeDB cluster i...
greptime/greptimedb-operator 0.2.9 0.1.3-alpha.1 The greptimedb-operator Helm chart for Kubernetes.
greptime/greptimedb-standalone 0.1.27 0.9.5 A Helm chart for deploying standalone greptimedb
安装和验证 GreptimeDB Operator
现在我们准备使用 Helm 在 Kubernetes 集群上安装 GreptimeDB Operator。
安装 GreptimeDB Operator
GreptimeDB Operator 是一个用于管理 GreptimeDB 集群生命周期的 Kubernetes operator。
让我们在 greptimedb-admin 命名空间中安装最新版本的 GreptimeDB Operator:
helm install greptimedb-operator greptime/greptimedb-operator -n greptimedb-admin --create-namespace
预期输出
NAME: greptimedb-operator
LAST DEPLOYED: Tue Oct 29 18:40:10 2024
NAMESPACE: greptimedb-admin
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-operator
Chart version: 0.2.9
GreptimeDB Operator version: 0.1.3-alpha.1
***********************************************************************
Installed components:
* greptimedb-operator
The greptimedb-operator is starting, use `kubectl get deployments greptimedb-operator -n greptimedb-admin` to check its status.
中国大陆用户如有网络访问问题,可直接使用阿里云 OCI 镜像仓库的方式安装 GreptimeDB Operator:
helm install greptimedb-operator \
oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/greptimedb-operator \
--set image.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
-n greptimedb-admin \
--create-namespace
此时我们也将镜像仓库设置为 Greptime 官方的阿里云镜像仓库。
我们还可以直接使用 kubectl 和 bundle.yaml 来安装最新版本的 GreptimeDB Operator:
kubectl apply -f \
https://github.com/GreptimeTeam/greptimedb-operator/releases/latest/download/bundle.yaml \
--server-side
这种方式仅适用于在测试环境快速部署 GreptimeDB Operator,不建议在生产环境中使用。
验证 GreptimeDB Operator 安装
检查 GreptimeDB Operator 的状态:
kubectl get pods -n greptimedb-admin -l app.kubernetes.io/instance=greptimedb-operator
预期输出
NAME READY STATUS RESTARTS AGE
greptimedb-operator-68d684c6cf-qr4q4 1/1 Running 0 4m8s
你也可以检查 CRD 的安装:
kubectl get crds | grep greptime
预期输出
greptimedbclusters.greptime.io 2024-10-28T08:46:27Z
greptimedbstandalones.greptime.io 2024-10-28T08:46:27Z
GreptimeDB Operator 将会使用 greptimedbclusters.greptime.io and greptimedbstandalones.greptime.io 这两个 CRD 来管理 GreptimeDB 集群和单机实例。
安装 etcd 集群
GreptimeDB 集群需要一个 etcd 集群来存储元数据。让我们使用 Bitnami 的 etcd Helm chart 来安装一个 etcd 集群。
helm install etcd \
oci://registry-1.docker.io/bitnamicharts/etcd \
--version 10.2.12 \
--set replicaCount=3 \
--set auth.rbac.create=false \
--set auth.rbac.token.enabled=false \
--create-namespace \
-n etcd-cluster
预期输出
NAME: etcd
LAST DEPLOYED: Mon Oct 28 17:01:38 2024
NAMESPACE: etcd-cluster
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: etcd
CHART VERSION: 10.2.12
APP VERSION: 3.5.15
** Please be patient while the chart is being deployed **
etcd can be accessed via port 2379 on the following DNS name from within your cluster:
etcd.etcd-cluster.svc.cluster.local
To create a pod that you can use as a etcd client run the following command:
kubectl run etcd-client --restart='Never' --image docker.io/bitnami/etcd:3.5.15-debian-12-r6 --env ETCDCTL_ENDPOINTS="etcd.etcd-cluster.svc.cluster.local:2379" --namespace etcd-cluster --command -- sleep infinity
Then, you can set/get a key using the commands below:
kubectl exec --namespace etcd-cluster -it etcd-client -- bash
etcdctl put /message Hello
etcdctl get /message
To connect to your etcd server from outside the cluster execute the following commands:
kubectl port-forward --namespace etcd-cluster svc/etcd 2379:2379 &
echo "etcd URL: http://127.0.0.1:2379"
WARNING: There are "resources" sections in the chart not set. Using "resourcesPreset" is not recommended for production. For production installations, please set the following values according to your workload needs:
- disasterRecovery.cronjob.resources
- resources
+info https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
当 etcd 集群准备好后,你可以使用以下命令检查 Pod 的状态:
kubectl get pods -n etcd-cluster -l app.kubernetes.io/instance=etcd
预期输出
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 2m8s
etcd-1 1/1 Running 0 2m8s
etcd-2 1/1 Running 0 2m8s
中国大陆用户如有网络访问问题,可直接使用阿里云 OCI 镜像仓库的方式安装 etcd 集群:
helm install etcd \
oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--set image.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
--set image.tag=3.5.12 \
--set replicaCount=3 \
--set auth.rbac.create=false \
--set auth.rbac.token.enabled=false \
--create-namespace \
-n etcd-cluster
你可以通过运行以下命令来测试 etcd 集群:
kubectl -n etcd-cluster \
exec etcd-0 -- etcdctl endpoint health \
--endpoints=http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379,http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379,http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379
预期输出
http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.008575ms
http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.136576ms
http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.147702ms
安装带有自监控的 GreptimeDB 集群
目前我们已经准备好了 GreptimeDB Operator 和 etcd 集群,现在我们可以部署一个带自监控并启用 Flow 功能的最小 GreptimeDB 集群:
本文档中的默认配置不适用于生产环境,你应该根据自己的需求调整配置。
helm install mycluster \
--set flownode.enabled=true \
--set monitoring.enabled=true \
--set grafana.enabled=true \
greptime/greptimedb-cluster \
-n default
中国大陆用户如有网络访问问题,可直接使用阿里云 OCI 镜像仓库的方式来安装 GreptimeDB 集群:
helm install mycluster \
oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/greptimedb-cluster \
--set image.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
--set initializer.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
--set grafana.enabled=true \
--set grafana.image.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
--set flownode.enabled=true \
--set monitoring.enabled=true \
--set monitoring.vector.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
-n default
如果你使用了不同的集群名称和命名空间,请将 mycluster 和 default 替换为你的配置。
预期输出
Release "mycluster" does not exist. Installing it now.
NAME: mycluster
LAST DEPLOYED: Mon Oct 28 17:19:47 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
***********************************************************************
Welcome to use greptimedb-cluster
Chart version: 0.2.25
GreptimeDB Cluster version: 0.9.5
***********************************************************************
Installed components:
* greptimedb-frontend
* greptimedb-datanode
* greptimedb-meta
The greptimedb-cluster is starting, use `kubectl get pods -n default` to check its status.
当同时启用 monitoring 和 grafana 选项时,我们将对 GreptimeDB 集群启动自监控:启动一个 GreptimeDB standalone 实例来监控 GreptimeDB 集群,并将相应的监控数据用 Grafana 进行渲染,从而更方便地排查 GreptimeDB 集群使用中的问题。
我们将会在 cluster 所属的命名空间下部署一个名为 ${cluster}-monitor 的 GreptimeDB standalone 实例,用于存储集群的 metrics 和 logs 这类监控数据。同时,我们也会为集群内的每一个 Pod 部署一个 Vector sidecar 来收集集群的 metrics 和 logs,并发送给 GreptimeDB standalone 实例。
我们也将会部署一个 Grafana 实例,并配置 Grafana 使用 GreptimeDB standalone 实例作为数据源(分别使用 Prometheus 和 MySQL 协议),从而我们开箱即可使用 Grafana 来可视化 GreptimeDB 集群的监控数据。默认地,Grafana 将会使用 mycluster 和 default 作为集群名称和命名空间来创建数据源。如果你想要监控具有不同名称或不同命名空间的集群,那就需要基于不同的集群名称和命名空间来创建不同的数据源配置。你可以创建一个如下所示的 values.yaml 文件:
grafana:
datasources:
datasources.yaml:
datasources:
- name: greptimedb-metrics
type: prometheus
url: http://${cluster}-monitor-standalone.${namespace}.svc.cluster.local:4000/v1/prometheus
access: proxy
isDefault: true
- name: greptimedb-logs
type: mysql
url: ${cluster}-monitor-standalone.${namespace}.svc.cluster.local:4002
access: proxy
database: public
上述配置将在 Grafana dashboard 中为 GreptimeDB 集群的指标和日志创建默认的数据源:
-
greptimedb-metrics:集群的指标存储在独立的监控数据库中,并对外暴露为 Prometheus 协议(type: prometheus); -
greptimedb-logs:集群的日志存储在独立的监控数据库中,并对外暴露为 MySQL 协议(type: mysql)。默认使用public数据库;
然后将上面的 values.yaml 中的 ${cluster} 和 ${namespace} 替换为你想要的值,并使用以下命令安装 GreptimeDB 集群:
helm install ${cluster} \
--set monitoring.enabled=true \
--set grafana.enabled=true \
greptime/greptimedb-cluster \
-f values.yaml \
-n ${namespace}
当启动集群安装之后,我们可以用如下命令检查 GreptimeDB 集群的状态。若你使用了不同的集群名和命名空间,可将 default 和 mycluster 替换为你的配置:
kubectl -n default get greptimedbclusters.greptime.io mycluster
预期输出
NAME FRONTEND DATANODE META FLOWNODE PHASE VERSION AGE
mycluster 1 1 1 0 Running v0.9.5 5m12s
上面的命令将会显示 GreptimeDB 集群的状态。当 PHASE 为 Running 时,表示 GreptimeDB 集群已经成功启动。
你还可以检查 GreptimeDB 集群的 Pod 状态:
kubectl -n default get pods
预期输出
NAME READY STATUS RESTARTS AGE
mycluster-datanode-0 2/2 Running 0 77s
mycluster-frontend-6ffdd549b-9s7gx 2/2 Running 0 66s
mycluster-grafana-675b64786-ktqps 1/1 Running 0 6m35s
mycluster-meta-58bc88b597-ppzvj 2/2 Running 0 86s
mycluster-monitor-standalone-0 1/1 Running 0 6m35s
正如你所看到的,我们默认创建了一个最小的 GreptimeDB 集群,包括 1 个 frontend、1 个 datanode 和 1 个 metasrv。关于一个完整的 GreptimeDB 集群的组成,你可以参考 architecture。除此之外,我们还部署了一个独立的 GreptimeDB standalone 实例(mycluster-monitor-standalone-0)用以存储监控数据和一个 Grafana 实例(mycluster-grafana-675b64786-ktqps)用以可视化集群的监控数据。
探索 GreptimeDB 集群
访问 GreptimeDB 集群
你可以通过使用 kubectl port-forward 命令转发 frontend 服务来访问 GreptimeDB 集群:
kubectl -n default port-forward svc/mycluster-frontend 4000:4000 4001:4001 4002:4002 4003:4003
预期输出
Forwarding from 127.0.0.1:4000 -> 4000
Forwarding from [::1]:4000 -> 4000
Forwarding from 127.0.0.1:4001 -> 4001
Forwarding from [::1]:4001 -> 4001
Forwarding from 127.0.0.1:4002 -> 4002
Forwarding from [::1]:4002 -> 4002
Forwarding from 127.0.0.1:4003 -> 4003
Forwarding from [::1]:4003 -> 4003
请注意,当你使用了其他集群名和命名空间时,你可以使用如下命令,并将 ${cluster} 和 ${namespace} 替换为你的配置:
kubectl -n ${namespace} port-forward svc/${cluster}-frontend 4000:4000 4001:4001 4002:4002 4003:4003
如果你想将服务暴露给公网访问,可以使用带有 --address 选项的 kubectl port-forward 命令:
kubectl -n default port-forward --address 0.0.0.0 svc/mycluster-frontend 4000:4000 4001:4001 4002:4002 4003:4003
在将服务暴露给公网访问之前,请确保你已经配置了适当的安全设置。
打开浏览器并访问 http://localhost:4000/dashboard 来访问 GreptimeDB Dashboard。
如果你想使用其他工具如 mysql 或 psql 来连接 GreptimeDB 集群,你可以参考 快速入门。
访问 Grafana dashboard
你可以使用 kubectl port-forward 命令转发 Grafana 服务:
kubectl -n default port-forward svc/mycluster-grafana 18080:80
请注意,当你使用了其他集群名和命名空间时,你可以使用如下命令,并将 ${cluster} 和 ${namespace} 替换为你的配置:
kubectl -n ${namespace} port-forward svc/${cluster}-grafana 18080:80
接着打开浏览器并访问 http://localhost:18080 来访问 Grafana dashboard。默认的用户名和密码是 admin 和 gt-operator:
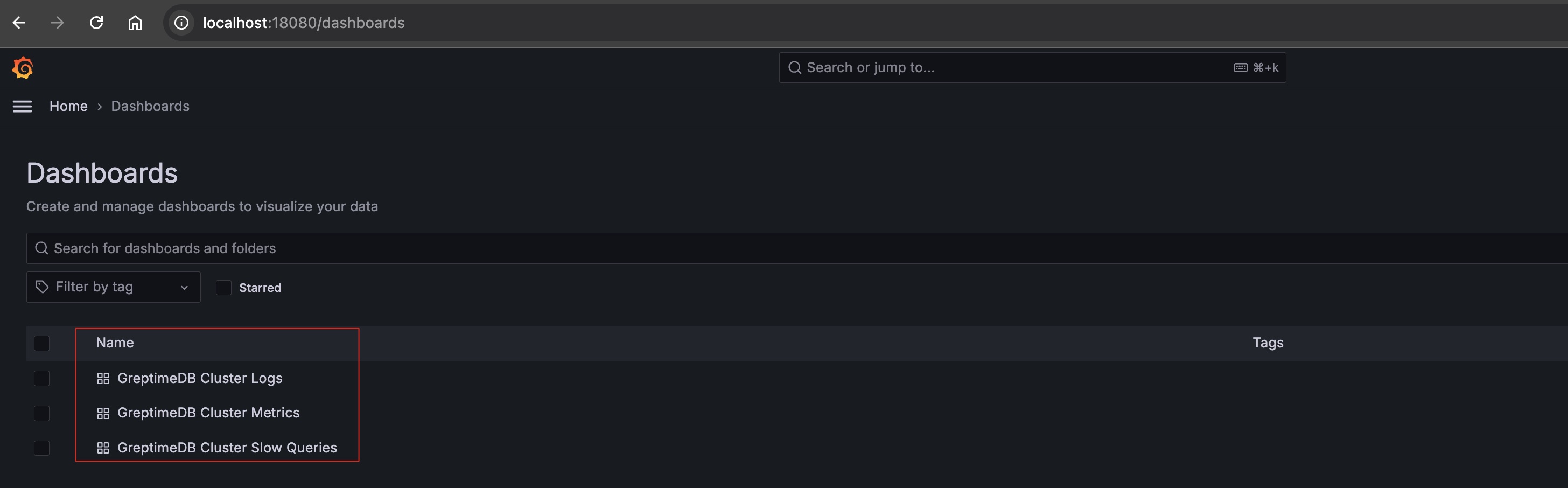
目前有三个可用的 Dashboard:
- GreptimeDB Cluster Metrics: 用于显示 GreptimeDB 集群的 Metrics;
- GreptimeDB Cluster Logs: 用于显示 GreptimeDB 集群的日志;
- GreptimeDB Cluster Slow Queries: 用于显示 GreptimeDB 集群的慢查询;
清理
清理操作将会删除 GreptimeDB 集群的元数据和数据。请确保在继续操作之前已经备份了数据。
停止端口转发
可以使用以下命令停止 GreptimeDB 集群的端口转发:
pkill -f kubectl port-forward
卸载 GreptimeDB 集群
可以使用以下命令卸载 GreptimeDB 集群:
helm -n default uninstall mycluster
删除 PVCs
为了安全起见,PVCs 默认不会被删除。如果你想删除 PV 数据,你可以使用以下命令:
kubectl -n default delete pvc -l app.greptime.io/component=mycluster-datanode
kubectl -n default delete pvc -l app.greptime.io/component=mycluster-monitor-standalone
清理 etcd 数据
你可以使用以下命令清理 etcd 集群:
kubectl -n etcd-cluster exec etcd-0 -- etcdctl del "" --from-key=true
删除 Kubernetes 集群
如果你使用 kind 创建 Kubernetes 集群,你可以使用以下命令销毁集群:
kind delete cluster