Deploy GreptimeDB Cluster
In this guide, you will learn how to deploy a GreptimeDB cluster on Kubernetes using the GreptimeDB Operator.
The following output may have minor differences depending on the versions of the Helm charts and environment.
Prerequisites
Create a test Kubernetes cluster
Using kind is not recommended for production environments or performance testing. For such use cases, we recommend using cloud-managed Kubernetes services such as Amazon EKS, Google GKE, or Azure AKS, or deploying your own production-grade Kubernetes cluster.
There are many ways to create a Kubernetes cluster for testing purposes. In this guide, we will use kind to create a local Kubernetes cluster. You can skip this step if you want to use the existing Kubernetes cluster.
Here is an example using kind v0.20.0:
kind create cluster
Expected Output
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.27.3) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Thanks for using kind! 😊
Check the status of the cluster:
kubectl cluster-info
Expected Output
Kubernetes control plane is running at https://127.0.0.1:60495
CoreDNS is running at https://127.0.0.1:60495/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Add the Greptime Helm repository
We provide the official Helm repository for the GreptimeDB Operator and GreptimeDB cluster. You can add the repository by running the following command:
helm repo add greptime https://greptimeteam.github.io/helm-charts/
helm repo update
Check the charts in the Greptime Helm repository:
helm search repo greptime
Expected Output
NAME CHART VERSION APP VERSION DESCRIPTION
greptime/greptimedb-cluster 0.2.25 0.9.5 A Helm chart for deploying GreptimeDB cluster i...
greptime/greptimedb-operator 0.2.9 0.1.3-alpha.1 The greptimedb-operator Helm chart for Kubernetes.
greptime/greptimedb-standalone 0.1.27 0.9.5 A Helm chart for deploying standalone greptimedb
Install and verify the GreptimeDB Operator
It's ready to use Helm to install the GreptimeDB Operator on the Kubernetes cluster.
Install the GreptimeDB Operator
The GreptimeDB Operator is a Kubernetes operator that manages the lifecycle of GreptimeDB cluster.
Let's install the latest version of the GreptimeDB Operator in the greptimedb-admin namespace:
helm install greptimedb-operator greptime/greptimedb-operator -n greptimedb-admin --create-namespace
Expected Output
NAME: greptimedb-operator
LAST DEPLOYED: Tue Oct 29 18:40:10 2024
NAMESPACE: greptimedb-admin
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-operator
Chart version: 0.2.9
GreptimeDB Operator version: 0.1.3-alpha.1
***********************************************************************
Installed components:
* greptimedb-operator
The greptimedb-operator is starting, use `kubectl get deployments greptimedb-operator -n greptimedb-admin` to check its status.
There is another way to install the GreptimeDB Operator by using kubectl and bundle.yaml from the latest release:
kubectl apply -f \
https://github.com/GreptimeTeam/greptimedb-operator/releases/latest/download/bundle.yaml \
--server-side
This method is only suitable for quickly deploying GreptimeDB Operator in the test environments and is not recommended for production use.
Verify the GreptimeDB Operator installation
Check the status of the GreptimeDB Operator:
kubectl get pods -n greptimedb-admin -l app.kubernetes.io/instance=greptimedb-operator
Expected Output
NAME READY STATUS RESTARTS AGE
greptimedb-operator-68d684c6cf-qr4q4 1/1 Running 0 4m8s
You also can check the CRD installation:
kubectl get crds | grep greptime
Expected Output
greptimedbclusters.greptime.io 2024-10-28T08:46:27Z
greptimedbstandalones.greptime.io 2024-10-28T08:46:27Z
The GreptimeDB Operator will use greptimedbclusters.greptime.io and greptimedbstandalones.greptime.io CRDs to manage GreptimeDB cluster and standalone resources.
Install the etcd cluster
The GreptimeDB cluster requires an etcd cluster for metadata storage. Let's install an etcd cluster using Bitnami's etcd Helm chart.
helm install etcd \
oci://registry-1.docker.io/bitnamicharts/etcd \
--version 10.2.12 \
--set replicaCount=3 \
--set auth.rbac.create=false \
--set auth.rbac.token.enabled=false \
--create-namespace \
-n etcd-cluster
Expected Output
NAME: etcd
LAST DEPLOYED: Mon Oct 28 17:01:38 2024
NAMESPACE: etcd-cluster
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: etcd
CHART VERSION: 10.2.12
APP VERSION: 3.5.15
** Please be patient while the chart is being deployed **
etcd can be accessed via port 2379 on the following DNS name from within your cluster:
etcd.etcd-cluster.svc.cluster.local
To create a pod that you can use as a etcd client run the following command:
kubectl run etcd-client --restart='Never' --image docker.io/bitnami/etcd:3.5.15-debian-12-r6 --env ETCDCTL_ENDPOINTS="etcd.etcd-cluster.svc.cluster.local:2379" --namespace etcd-cluster --command -- sleep infinity
Then, you can set/get a key using the commands below:
kubectl exec --namespace etcd-cluster -it etcd-client -- bash
etcdctl put /message Hello
etcdctl get /message
To connect to your etcd server from outside the cluster execute the following commands:
kubectl port-forward --namespace etcd-cluster svc/etcd 2379:2379 &
echo "etcd URL: http://127.0.0.1:2379"
WARNING: There are "resources" sections in the chart not set. Using "resourcesPreset" is not recommended for production. For production installations, please set the following values according to your workload needs:
- disasterRecovery.cronjob.resources
- resources
+info https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
Wait for the etcd cluster to be ready:
kubectl get pods -n etcd-cluster -l app.kubernetes.io/instance=etcd
Expected Output
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 2m8s
etcd-1 1/1 Running 0 2m8s
etcd-2 1/1 Running 0 2m8s
You can test the etcd cluster by running the following command:
kubectl -n etcd-cluster \
exec etcd-0 -- etcdctl endpoint health \
--endpoints=http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379,http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379,http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379
Expected Output
http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.008575ms
http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.136576ms
http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.147702ms
Install the GreptimeDB cluster with self-monitoring
Now that the GreptimeDB Operator and etcd cluster are installed, you can deploy a minimum GreptimeDB cluster with self-monitoring and Flow enabled:
The default configuration for the GreptimeDB cluster is not recommended for production use. You should adjust the configuration according to your requirements.
helm install mycluster \
--set monitoring.enabled=true \
--set grafana.enabled=true \
--set flownode.enabled=true \
greptime/greptimedb-cluster \
-n default
Expected Output
Release "mycluster" does not exist. Installing it now.
NAME: mycluster
LAST DEPLOYED: Mon Oct 28 17:19:47 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
***********************************************************************
Welcome to use greptimedb-cluster
Chart version: 0.2.25
GreptimeDB Cluster version: 0.9.5
***********************************************************************
Installed components:
* greptimedb-frontend
* greptimedb-datanode
* greptimedb-meta
The greptimedb-cluster is starting, use `kubectl get pods -n default` to check its status.
When both monitoring and grafana options are enabled, we will enable self-monitoring for the GreptimeDB cluster: a GreptimeDB standalone instance will be deployed to monitor the GreptimeDB cluster, and the monitoring data will be visualized using Grafana, making it easier to troubleshoot issues in the GreptimeDB cluster.
We will deploy a GreptimeDB standalone instance named ${cluster}-monitor in the same namespace as the cluster to store monitoring data such as metrics and logs from the cluster. Additionally, we will deploy a Vector sidecar for each pod in the cluster to collect metrics and logs and send them to the GreptimeDB standalone instance.
We will deploy a Grafana instance and configure it to use the GreptimeDB standalone instance as a data source (using both Prometheus and MySQL protocols), allowing us to visualize the GreptimeDB cluster's monitoring data out of the box. By default, Grafana will use mycluster and default as the cluster name and namespace to create data sources. If you want to monitor clusters with different names or namespaces, you'll need to create different data source configurations based on the cluster names and namespaces. You can create a values.yaml file like this:
grafana:
datasources:
datasources.yaml:
datasources:
- name: greptimedb-metrics
type: prometheus
url: http://${cluster}-monitor-standalone.${namespace}.svc.cluster.local:4000/v1/prometheus
access: proxy
isDefault: true
- name: greptimedb-logs
type: mysql
url: ${cluster}-monitor-standalone.${namespace}.svc.cluster.local:4002
access: proxy
database: public
The above configuration will create the default datasources for the GreptimeDB cluster metrics and logs in the Grafana dashboard:
-
greptimedb-metrics: The metrics of the cluster are stored in the standalone monitoring database and exposed in Prometheus protocol (type: prometheus); -
greptimedb-logs: The logs of the cluster are stored in the standalone monitoring database and exposed in MySQL protocol (type: mysql). It uses thepublicdatabase by default;
Then replace {cluster} and ${namespace} with your desired values and install the GreptimeDB cluster using the following command (please note that {cluster} and ${namespace} in the command also need to be replaced):
helm install {cluster} \
--set monitoring.enabled=true \
--set grafana.enabled=true \
greptime/greptimedb-cluster \
-f values.yaml \
-n ${namespace}
When starting the cluster installation, we can check the status of the GreptimeDB cluster with the following command. If you use a different cluster name and namespace, you can replace mycluster and default with your configuration:
kubectl -n default get greptimedbclusters.greptime.io mycluster
Expected Output
NAME FRONTEND DATANODE META FLOWNODE PHASE VERSION AGE
mycluster 1 1 1 0 Running v0.9.5 5m12s
The above command will show the status of the GreptimeDB cluster. When the PHASE is Running, it means the GreptimeDB cluster has been successfully started.
You also can check the Pods status of the GreptimeDB cluster:
kubectl -n default get pods
Expected Output
NAME READY STATUS RESTARTS AGE
mycluster-datanode-0 2/2 Running 0 77s
mycluster-frontend-6ffdd549b-9s7gx 2/2 Running 0 66s
mycluster-grafana-675b64786-ktqps 1/1 Running 0 6m35s
mycluster-meta-58bc88b597-ppzvj 2/2 Running 0 86s
mycluster-monitor-standalone-0 1/1 Running 0 6m35s
As you can see, we have created a minimal GreptimeDB cluster consisting of 1 frontend, 1 datanode, and 1 metasrv by default. For information about the components of a complete GreptimeDB cluster, you can refer to architecture. Additionally, we have deployed a standalone GreptimeDB instance (mycluster-monitor-standalone-0) for storing monitoring data and a Grafana instance (mycluster-grafana-675b64786-ktqps) for visualizing the cluster's monitoring data.
Explore the GreptimeDB cluster
For production use, you should access the GreptimeDB cluster or Grafana inside the Kubernetes cluster or using the LoadBalancer type service.
Access the GreptimeDB cluster
You can access the GreptimeDB cluster by using kubectl port-forward the frontend service:
kubectl -n default port-forward svc/mycluster-frontend 4000:4000 4001:4001 4002:4002 4003:4003
Expected Output
Forwarding from 127.0.0.1:4000 -> 4000
Forwarding from [::1]:4000 -> 4000
Forwarding from 127.0.0.1:4001 -> 4001
Forwarding from [::1]:4001 -> 4001
Forwarding from 127.0.0.1:4002 -> 4002
Forwarding from [::1]:4002 -> 4002
Forwarding from 127.0.0.1:4003 -> 4003
Forwarding from [::1]:4003 -> 4003
Please note that when you use a different cluster name and namespace, you can use the following command, and replace ${cluster} and ${namespace} with your configuration:
kubectl -n ${namespace} port-forward svc/${cluster}-frontend 4000:4000 4001:4001 4002:4002 4003:4003
If you want to expose the service to the public, you can use the kubectl port-forward command with the --address option:
kubectl -n default port-forward --address 0.0.0.0 svc/mycluster-frontend 4000:4000 4001:4001 4002:4002 4003:4003
Please make sure you have the proper security settings in place before exposing the service to the public.
Open the browser and navigate to http://localhost:4000/dashboard to access by the GreptimeDB Dashboard.
If you want to use other tools like mysql or psql to connect to the GreptimeDB cluster, you can refer to the Quick Start.
Access the Grafana dashboard
You can access the Grafana dashboard by using kubctl port-forward the Grafana service:
kubectl -n default port-forward svc/mycluster-grafana 18080:80
Please note that when you use a different cluster name and namespace, you can use the following command, and replace ${cluster} and ${namespace} with your configuration:
kubectl -n ${namespace} port-forward svc/${cluster}-grafana 18080:80
Then open your browser and navigate to http://localhost:18080 to access the Grafana dashboard. The default username and password are admin and gt-operator:
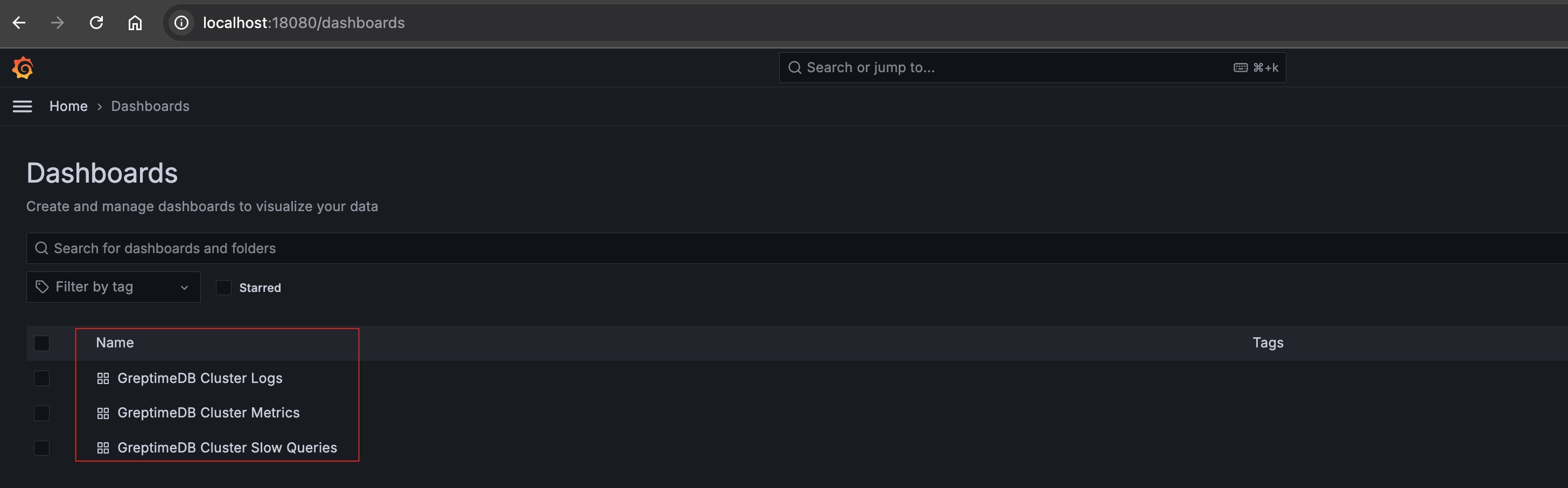
There are three dashboards available:
- GreptimeDB Cluster Metrics: Displays the metrics of the GreptimeDB cluster.
- GreptimeDB Cluster Logs: Displays the logs of the GreptimeDB cluster.
- GreptimeDB Cluster Slow Queries: Displays the slow queries of the GreptimeDB cluster.
Cleanup
The cleanup operation will remove the metadata and data of the GreptimeDB cluster. Please make sure you have backed up the data before proceeding.
Stop the port-forwarding
Stop the port-forwarding for the GreptimeDB cluster:
pkill -f kubectl port-forward
Uninstall the GreptimeDB cluster
To uninstall the GreptimeDB cluster, you can use the following command:
helm -n default uninstall mycluster
Delete the PVCs
The PVCs wouldn't be deleted by default for safety reasons. If you want to delete the PV data, you can use the following command:
kubectl -n default delete pvc -l app.greptime.io/component=mycluster-datanode
kubectl -n default delete pvc -l app.greptime.io/component=mycluster-monitor-standalone
Cleanup the etcd cluster
You can use the following command to clean up the etcd cluster:
kubectl -n etcd-cluster exec etcd-0 -- etcdctl del "" --from-key=true
Destroy the Kubernetes cluster
If you are using kind to create the Kubernetes cluster, you can use the following command to destroy the cluster:
kind delete cluster