Define a Function
Coprocessor annotation
The @coprocessor annotation specifies a python function as a coprocessor in GreptimeDB and sets some attributes for it.
The engine allows one and only one function annotated with @coprocessor. We can't have more than one coprocessor in one script.
| Parameter | Description | Example |
|---|---|---|
sql | Optional. The SQL statement that the coprocessor function will query data from the database and assign them to input args. | @copr(sql="select * from cpu", ..) |
args | Optional. The argument names that the coprocessor function will be taken as input, which are the columns in query results by sql. | @copr(args=["cpu", "mem"], ..) |
returns | The column names that the coprocessor function will return. The Coprocessor Engine uses it to generate the output schema. | @copr(returns=["add", "sub", "mul", "div"], ..) |
backend | Optional. The coprocessor function will run on available engines like rspy and pyo3, which are associated with RustPython Backend and CPython Backend respectively. The default engine is set to rspy. | @copr(backend="rspy", ..) |
Both sql and args are optional; they must either be provided together or not at all. They are usually used in Post-Query processing. Please read below.
The returns is required for every coprocessor because the output schema is necessary.
backend is optional, because RustPython can't support C APIs and you might want to use pyo3 backend to use third-party python libraries that only support C APIs. For example, numpy, pandas etc.
Input of the coprocessor function
@coprocessor(args=["number"], sql="select number from numbers limit 20", returns=["value"])
def normalize(v) -> vector[i64]:
return [normalize0(x) for x in v]@coprocessor(args=["number"], sql="select number from numbers limit 20", returns=["value"])
def normalize(v) -> vector[i64]:
return [normalize0(x) for x in v]The argument v is the number column(specified by the args attribute) in query results that are returned by executing the sql.
Of course, you can have several arguments:
@coprocessor(args=["number", "number", "number"],
sql="select number from numbers limit 5",
returns=["value"])
def normalize(n1, n2, n3) -> vector[i64]:
# returns [0,1,8,27,64]
return n1 * n2 * n3@coprocessor(args=["number", "number", "number"],
sql="select number from numbers limit 5",
returns=["value"])
def normalize(n1, n2, n3) -> vector[i64]:
# returns [0,1,8,27,64]
return n1 * n2 * n3Except args, we can also pass user-defined parameters into the coprocessor:
@coprocessor(returns=['value'])
def add(**params) -> vector[i64]:
a = params['a']
b = params['b']
return int(a) + int(b)@coprocessor(returns=['value'])
def add(**params) -> vector[i64]:
a = params['a']
b = params['b']
return int(a) + int(b)And then pass the a and b from HTTP API:
curl -XPOST \
"http://localhost:4000/v1/run-script?name=add&db=public&a=42&b=99"curl -XPOST \
"http://localhost:4000/v1/run-script?name=add&db=public&a=42&b=99"{
"code": 0,
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "value",
"data_type": "Int64"
}
]
},
"rows": [
[
141
]
]
}
}
],
"execution_time_ms": 0
}{
"code": 0,
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "value",
"data_type": "Int64"
}
]
},
"rows": [
[
141
]
]
}
}
],
"execution_time_ms": 0
}We pass a=42&b=99 as query params into HTTP API, and it returns the result 141.
The user-defined parameters must be defined by **kwargs in the coprocessor, and all their types are strings. We can pass anything we want such as SQL to run in the coprocessor.
Output of the coprocessor function
As we have seen in the previous examples, the output must be vectors.
We can return multi vectors:
from greptime import vector
@coprocessor(returns=["a", "b", "c"])
def return_vectors() -> (vector[i64], vector[str], vector[f64]):
a = vector([1, 2, 3])
b = vector(["a", "b", "c"])
c = vector([42.0, 43.0, 44.0])
return a, b, cfrom greptime import vector
@coprocessor(returns=["a", "b", "c"])
def return_vectors() -> (vector[i64], vector[str], vector[f64]):
a = vector([1, 2, 3])
b = vector(["a", "b", "c"])
c = vector([42.0, 43.0, 44.0])
return a, b, cThe return types of function return_vectors is (vector[i64], vector[str], vector[f64]).
But we must ensure that all these vectors returned by the function have the same length. Because when they are converted into rows, each row must have all the column values presented.
Of course, we can return literal values, and they will be turned into vectors:
from greptime import vector
@coprocessor(returns=["a", "b", "c"])
def return_vectors() -> (vector[i64], vector[str], vector[i64]):
a = 1
b = "Hello, GreptimeDB!"
c = 42
return a, b, cfrom greptime import vector
@coprocessor(returns=["a", "b", "c"])
def return_vectors() -> (vector[i64], vector[str], vector[i64]):
a = 1
b = "Hello, GreptimeDB!"
c = 42
return a, b, cHTTP API
/scripts submits a Python script into GreptimeDB.
Save a python script such as test.py:
@coprocessor(args = ["number"],
returns = [ "number" ],
sql = "select number from numbers limit 5")
def square(number) -> vector[i64]:
return number * 2@coprocessor(args = ["number"],
returns = [ "number" ],
sql = "select number from numbers limit 5")
def square(number) -> vector[i64]:
return number * 2Submits it to database:
curl --data-binary @test.py -XPOST \
"http://localhost:4000/v1/scripts?db=default&name=square"curl --data-binary @test.py -XPOST \
"http://localhost:4000/v1/scripts?db=default&name=square"{"code":0}{"code":0}The python script is inserted into the scripts table and compiled automatically:
curl -G http://localhost:4000/v1/sql --data-urlencode "sql=select * from scripts"curl -G http://localhost:4000/v1/sql --data-urlencode "sql=select * from scripts"{
"code": 0,
"output": [{
"records": {
"schema": {
"column_schemas": [
{
"name": "schema",
"data_type": "String"
},
{
"name": "name",
"data_type": "String"
},
{
"name": "script",
"data_type": "String"
},
{
"name": "engine",
"data_type": "String"
},
{
"name": "timestamp",
"data_type": "TimestampMillisecond"
},
{
"name": "gmt_created",
"data_type": "TimestampMillisecond"
},
{
"name": "gmt_modified",
"data_type": "TimestampMillisecond"
}
]
},
"rows": [
[
"default",
"square",
"@coprocessor(args = [\"number\"],\n returns = [ \"number\" ],\n sql = \"select number from numbers\")\ndef square(number):\n return number * 2\n",
"python",
0,
1676032587204,
1676032587204
]
]
}
}],
"execution_time_ms": 4
}{
"code": 0,
"output": [{
"records": {
"schema": {
"column_schemas": [
{
"name": "schema",
"data_type": "String"
},
{
"name": "name",
"data_type": "String"
},
{
"name": "script",
"data_type": "String"
},
{
"name": "engine",
"data_type": "String"
},
{
"name": "timestamp",
"data_type": "TimestampMillisecond"
},
{
"name": "gmt_created",
"data_type": "TimestampMillisecond"
},
{
"name": "gmt_modified",
"data_type": "TimestampMillisecond"
}
]
},
"rows": [
[
"default",
"square",
"@coprocessor(args = [\"number\"],\n returns = [ \"number\" ],\n sql = \"select number from numbers\")\ndef square(number):\n return number * 2\n",
"python",
0,
1676032587204,
1676032587204
]
]
}
}],
"execution_time_ms": 4
}You can also execute the script via /run-script:
curl -XPOST -G "http://localhost:4000/v1/run-script?db=default&name=square"curl -XPOST -G "http://localhost:4000/v1/run-script?db=default&name=square"{
"code": 0,
"output": [{
"records": {
"schema": {
"column_schemas": [
{
"name": "number",
"data_type": "Float64"
}
]
},
"rows": [
[
0
],
[
2
],
[
4
],
[
6
],
[
8
]
]
}
}],
"execution_time_ms": 8
}{
"code": 0,
"output": [{
"records": {
"schema": {
"column_schemas": [
{
"name": "number",
"data_type": "Float64"
}
]
},
"rows": [
[
0
],
[
2
],
[
4
],
[
6
],
[
8
]
]
}
}],
"execution_time_ms": 8
}Parameters and Result for Python scripts
/scripts accepts query parameters db which specifies the database, and name which names the script. /scripts processes the POST method body as the script file content.
/run-script runs the compiled script by db and name, then returns the output which is the same as the query result in /sql API.
/run-script also receives other query parameters as the user params passed into the coprocessor, refer to Input and Output.
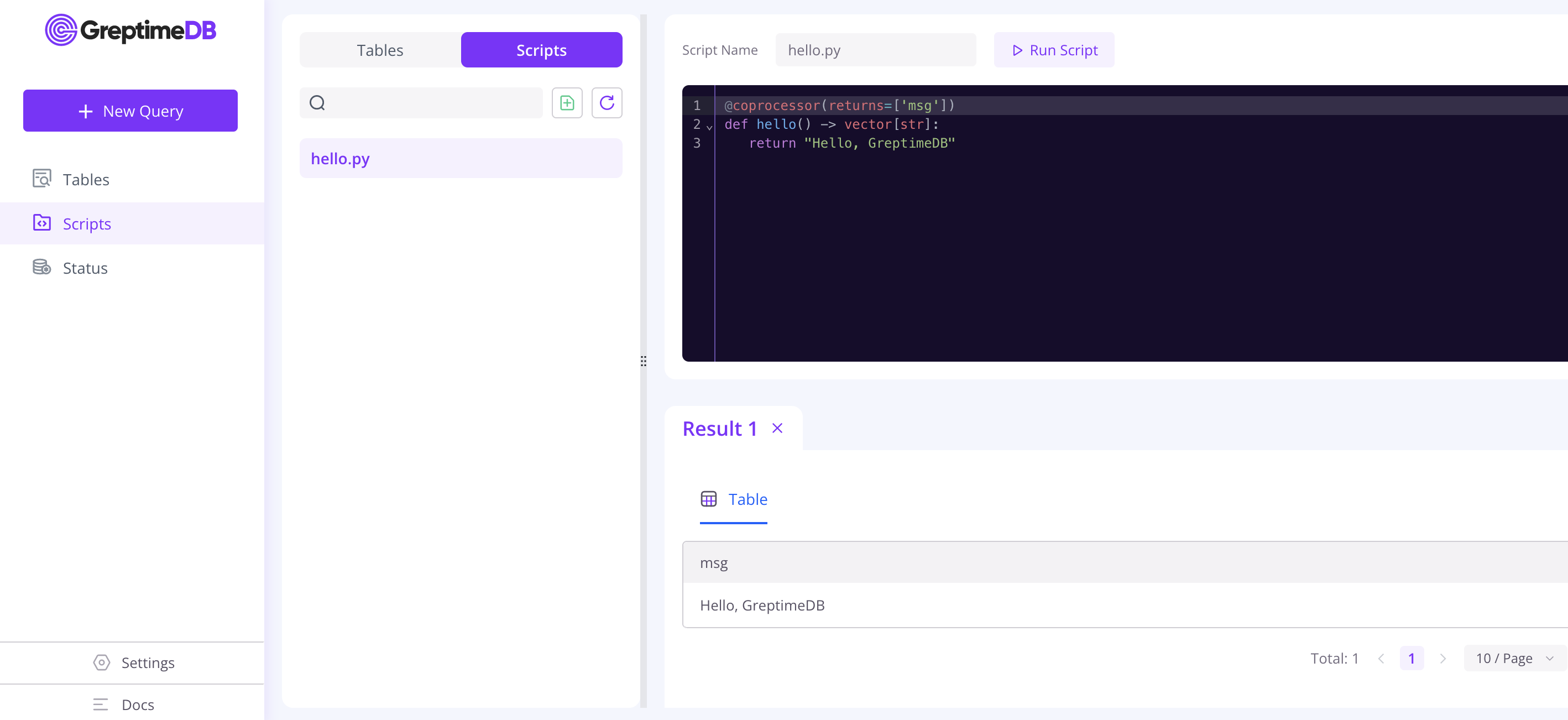
Edit scripts in GreptimeDB Dashboard
GreptimeDB Dashboard provides a convenient editor for users to edit scripts.
After starting GreptimeDB, you can access the dashboard at http://localhost:4000/dashboard. Click on Scripts in the left sidebar to navigate to the script page. From there, you can create a new script, edit an existing script, or run a script.